Overview
Kafka transactions are a powerful feature designed to ensure atomicity and consistency in data streaming applications. They enable developers to produce records across multiple partitions atomically and ensure exactly-once semantics for stream processing. This blog delves into the intricacies of Kafka transactions, exploring their concepts, implementation, configuration, common issues, and best practices. Drawing from authoritative sources such as Confluent, Conduktor, Redpanda, and others, this document provides a detailed understanding of Kafka transactions for both novice and experienced users.
Introduction to Kafka Transactions
Apache Kafka is a distributed event streaming platform widely used for building real-time data pipelines and stream processing applications. Transactions in Kafka were introduced to address the challenges of ensuring atomicity and consistency in scenarios where multiple operations need to be performed as a single logical unit. These transactions are particularly useful in applications that follow the consume-process-produce paradigm, where incoming messages are processed and new messages are produced based on the results.
The core idea behind Kafka transactions is to provide guarantees similar to those offered by database transactions. Specifically, Kafka transactions ensure that either all operations within a transaction succeed or none of them do. This atomicity is critical for preventing issues such as duplicate processing or data loss.
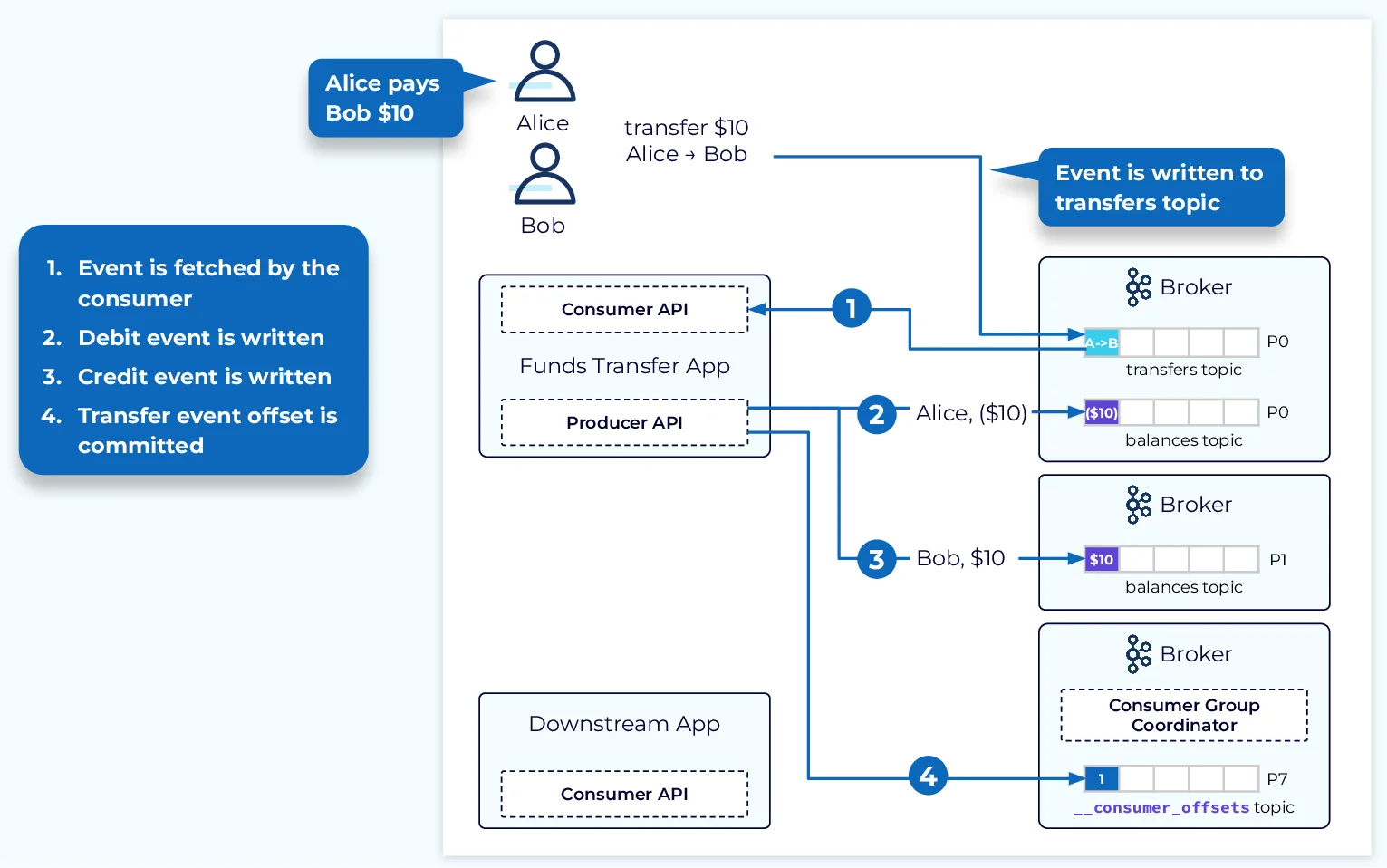
Core Concepts of Kafka Transactions
Atomicity in Kafka
Kafka transactions ensure atomicity by allowing producers to group multiple write operations into a single transaction. If the transaction commits successfully, all the writes are visible to consumers. If the transaction is aborted, none of the writes are visible. This guarantees that consumers only see complete and consistent data.
Exactly-Once Semantics
Exactly-once semantics (EOS) is a cornerstone of Kafka transactions. It ensures that each message is processed exactly once, even in the presence of failures. This is achieved through idempotent producers and transactional consumers configured with isolation levels.
Isolation Levels
Kafka supports two isolation levels: read_uncommitted and read_committed . The read_uncommitted isolation level allows consumers to see all records, including those from ongoing or aborted transactions. In contrast, the read_committed isolation level ensures that consumers only see records from committed transactions.
Transaction Coordinator
The transaction coordinator is a critical component in Kafka's architecture that manages transactional state. It tracks ongoing transactions using an internal topic called __transaction_state , ensuring durability and consistency across brokers.
How Kafka Transactions Work
Producer Workflow
A producer initiates a transaction by specifying a unique transactional.id . This ID is used by the transaction coordinator to track the transaction's state. The workflow typically involves the following steps:
-
Begin Transaction : The producer starts a new transaction.
-
Produce Messages : Messages are sent to various topic partitions as part of the transaction.
-
Send Offsets to Transaction : If consuming messages as part of the workflow, offsets are sent to the transaction.
-
Commit or Abort : The producer commits or aborts the transaction based on application logic.
Consumer Workflow
Transactional consumers must be configured with an isolation level of read_committed to ensure they only read committed messages. The consumer fetches records up to the Last Stable Offset (LSO), which marks the boundary between committed and uncommitted records.
Multiversion Concurrency Control (MVCC)
Kafka employs MVCC-like techniques to manage visibility of transactional records. Control records are inserted into logs to indicate transaction boundaries, enabling consumers to skip aborted records.
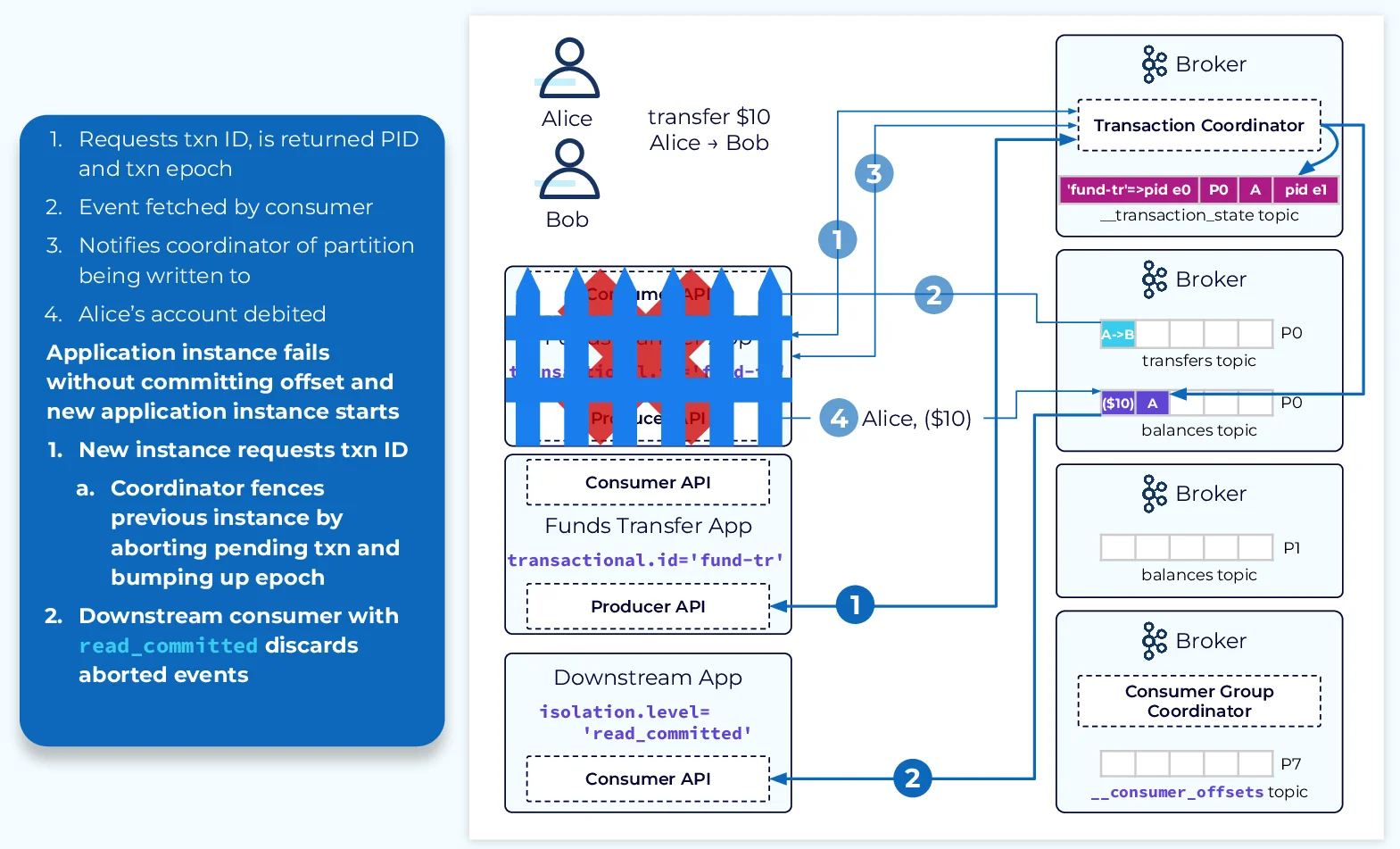
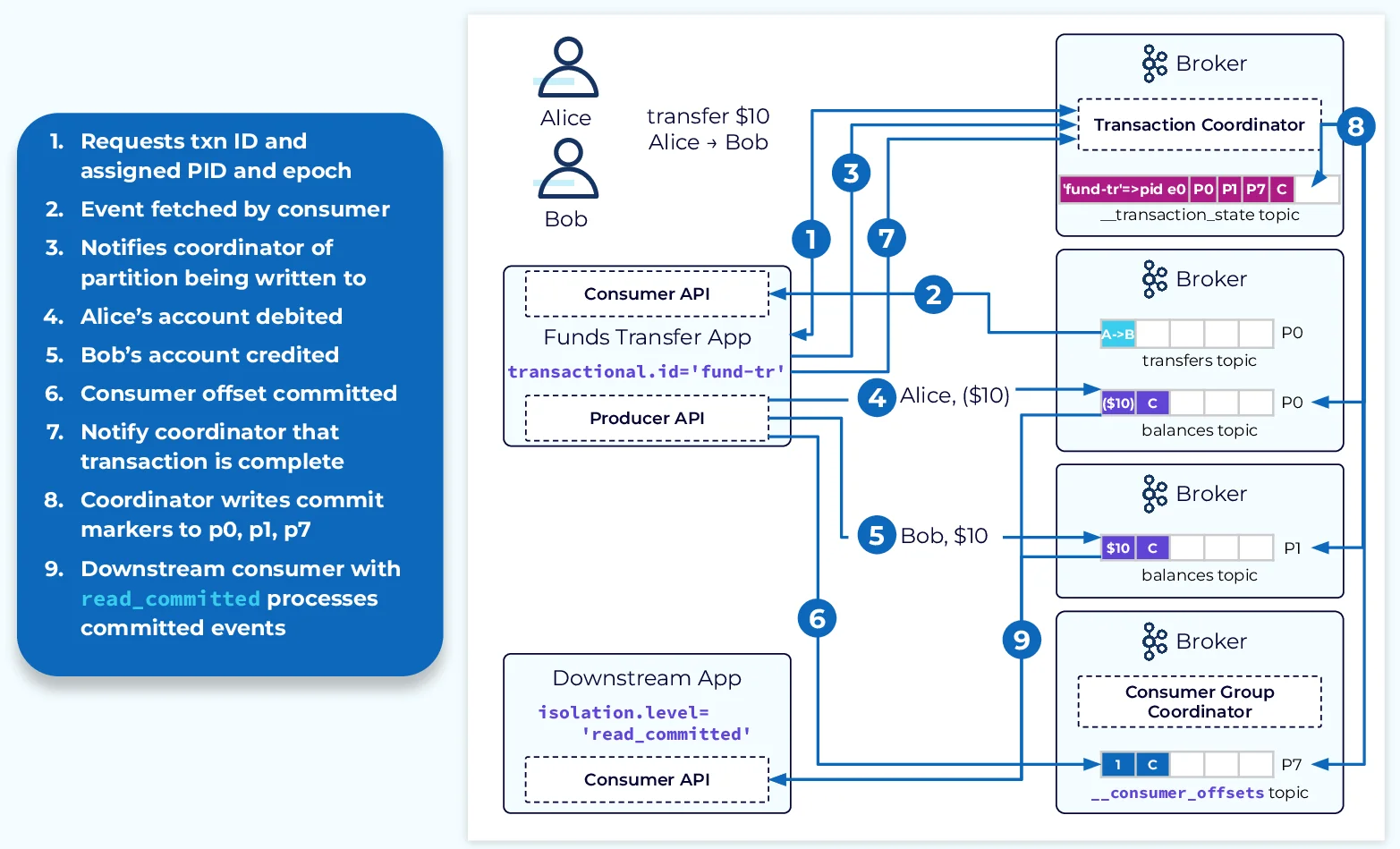
Configuration of Kafka Transactions
Producer Configuration
To enable transactional capabilities for a producer, several configurations must be set:
-
transactional.id: A unique identifier for the producer's transactional state.
-
enable.idempotence : Ensures idempotent message production.
-
transaction.timeout.ms: Specifies the timeout for transactions.
Consumer Configuration
Consumers must be configured with:
-
isolation.level=read_committed : Ensures visibility of only committed messages.
-
enable.auto.commit=false : Disables automatic offset commits.
Broker Configuration
Brokers require sufficient resources for managing transactional state:
-
transaction.state.log.replication.factor : Ensures durability by replicating transactional state logs.
-
transaction.state.log.min.isr : Specifies minimum in-sync replicas for transactional state logs.
Common Issues with Kafka Transactions
Hung Transactions
Hung transactions occur when producers fail to complete their transactions due to network issues or application crashes. These can prevent consumers from progressing past the Last Stable Offset (LSO). Tools like kafka-transactions.sh can be used to identify and abort hung transactions.
Zombie Instances
Zombie instances arise when multiple producers use the same transactional.id but operate with different epochs due to failures or restarts. Kafka mitigates this issue by fencing off older epochs.
Performance Overheads
Transactional operations introduce additional overhead due to coordination between brokers and replication of transactional state logs. Applications must carefully balance performance requirements against transactional guarantees.
Best Practices for Using Kafka Transactions
Design Considerations
-
Use transactions only when atomicity and exactly-once guarantees are essential.
-
Avoid overusing transactions for simple use cases where at-least-once semantics suffice.
Configuration Tips
-
Ensure proper replication factors for transactional state logs.
-
Configure appropriate timeouts (
transaction.timeout.ms) based on application needs.
Monitoring and Debugging
-
Monitor metrics related to transactional state logs and consumer lag.
-
Use tools like
kafka-transactions.shfor managing hung transactions.
Integration with External Systems
When integrating Kafka transactions with external systems like databases or REST APIs, consider using distributed transaction managers or idempotent consumer patterns.
Conclusion
Kafka transactions provide robust guarantees for atomicity and exactly-once semantics in stream processing applications. By understanding their underlying concepts, configuration options, common issues, and best practices, developers can leverage Kafka's transactional capabilities effectively. While they introduce additional complexity and overhead, their benefits in ensuring data consistency make them indispensable for critical applications.
This comprehensive exploration highlights the importance of careful planning and monitoring when using Kafka transactions, ensuring that they align with application requirements and system constraints.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


