Article Preview
This article comes from developers Ankur Ranjan and Sai Vineel Thamishetty from Walmart, who have long been following the evolution of Apache Kafka and stream processing systems, deeply studying the challenges and innovations faced by modern streaming architectures. The article not only summarizes Kafka’s historical value and current limitations but also showcases how the next-generation open-source project AutoMQ leverages cloud-native design to address Kafka’s pain points in cost, scalability, and operations, offering fresh perspectives for real-time data streaming architectures.
Kafka: Bridge between operational estate and analytical estate
I’ve been working with Apache Kafka for several years now, and I absolutely love it. As a Data Engineer, I’ve mostly used it as a bridge connecting the operational estate with the analytical estate. Kafka has long set the standard for stream processing with its elegant design and robust capabilities.
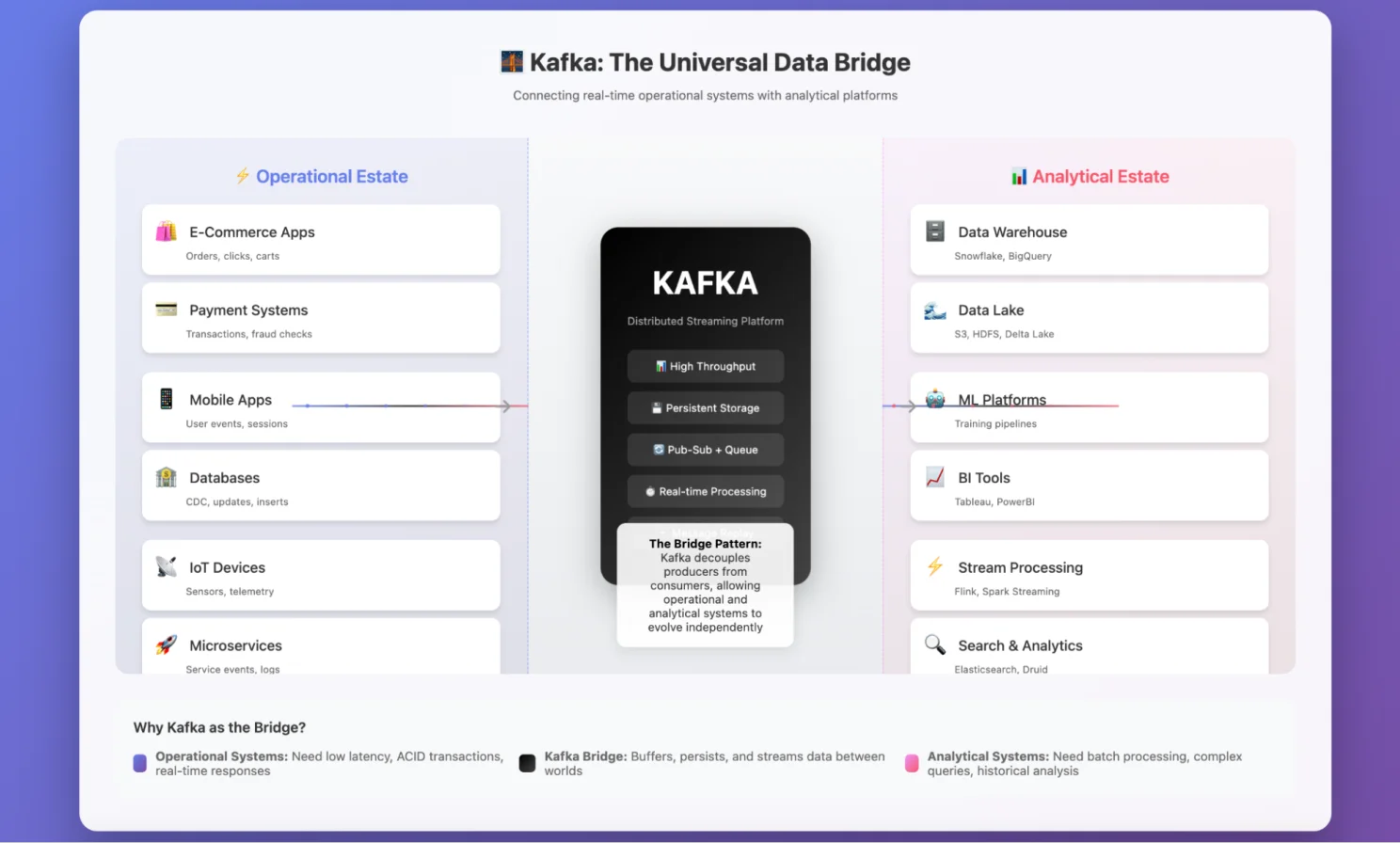
Since its inception, Kafka has shaped modern stream processing architectures with its unique distributed log abstraction. It not only offered unmatched capabilities for real-time data stream processing but also built an entire ecosystem around it.
Its success comes from one core strength: the ability to handle high throughput with low latency, at scale. This made it a dependable choice for businesses of all sizes—and eventually established Kafka as the industry standard for streaming.
But it hasn’t always been smooth sailing. Costs can balloon 🥹, and operational pain points like partition reassignments during peak traffic hours can be nerve-wracking 🫣.
I still remember my time at Walmart, spending hours debugging yet another partition reassignment that hit right in the middle of peak traffic. That one nearly gave me a heart attack 😀.
And yet, Kafka continues to dominate the streaming world despite its significant cost profile. In today’s cloud-first landscape, it’s almost surprising that a system designed years ago, around local disk storage, is still the backbone for so many companies.
After digging deeper, I realised the reason: Kafka isn’t “perfect.” It’s just that for a long time, there weren’t many suitable alternatives. Its biggest selling points—speed, durability, and reliability—still carry huge weight today.
But if you’ve worked with Kafka, you already know this: it stores everything on local disks. And that brings along a hidden set of costs and challenges—disk failures, scaling headaches, handling sudden traffic spikes, and being limited by on-prem or local storage capacity.
A few months ago, I stumbled onto an open-source project called AutoMQ. What started as casual research turned into a deep dive that reshaped how I think about streaming architectures.
So in this article, we want to share both the challenges of Kafka’s traditional storage model and how modern solutions like AutoMQ are approaching the problem differently—by leaning on cloud object storage instead of local disks. This shift makes Kafka more scalable, cost-effective, and cloud-friendly, while still keeping Kafka’s familiar API and ecosystem.
The Elephant in the Room: Why Kafka Feels Stuck in Time
Let's be honest – Kafka is brilliant. It revolutionised how we think about data streaming. But every time I provision those expensive EBS volumes, watch partition reassignments crawl for hours, or wake up at 3 AM because a broker ran out of disk space, I can't help but think: there has to be a better way.
The root of these problems? Kafka's shared-nothing architecture*.*
Each broker is like a hermit: it owns its data, guards it jealously on local disks, and refuses to share. This made perfect sense in 2011. We were running on-premise servers, and local disks were the only game in town. But in today's cloud world? It's like insisting on using filing cabinets when everyone else has moved to Google Drive.
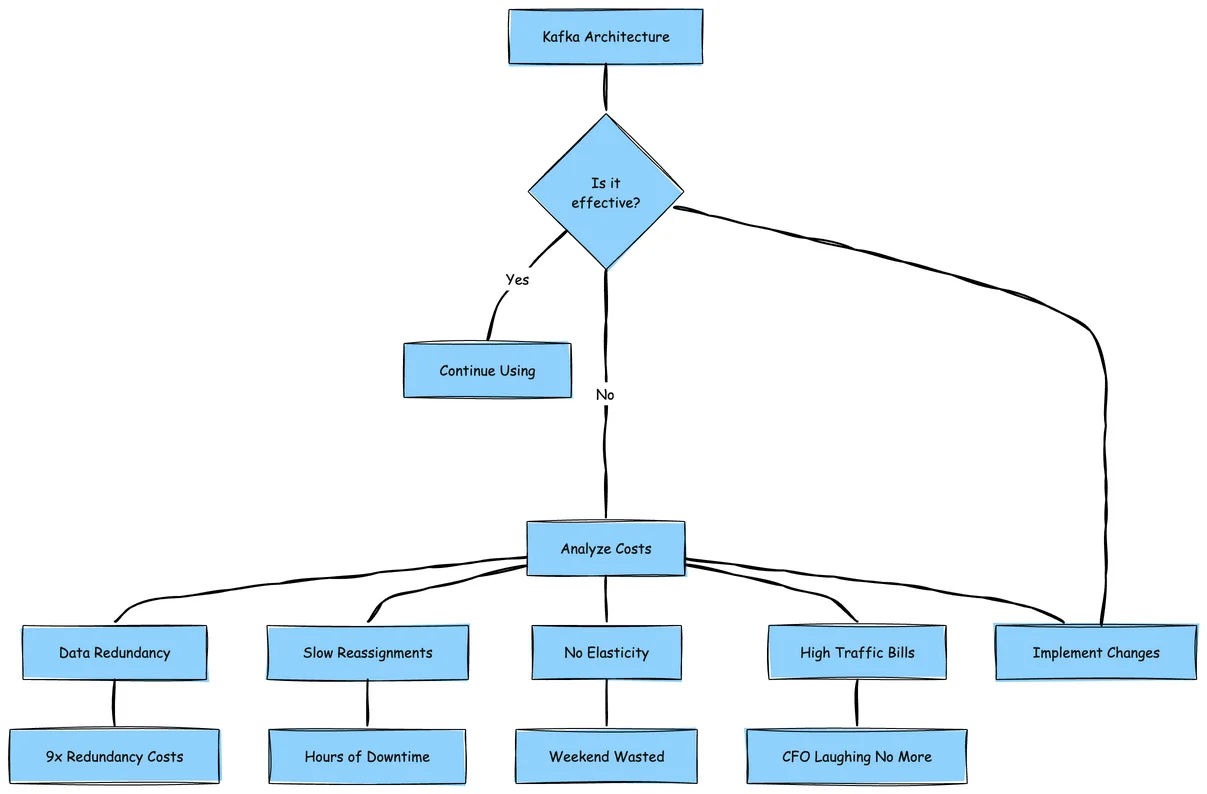
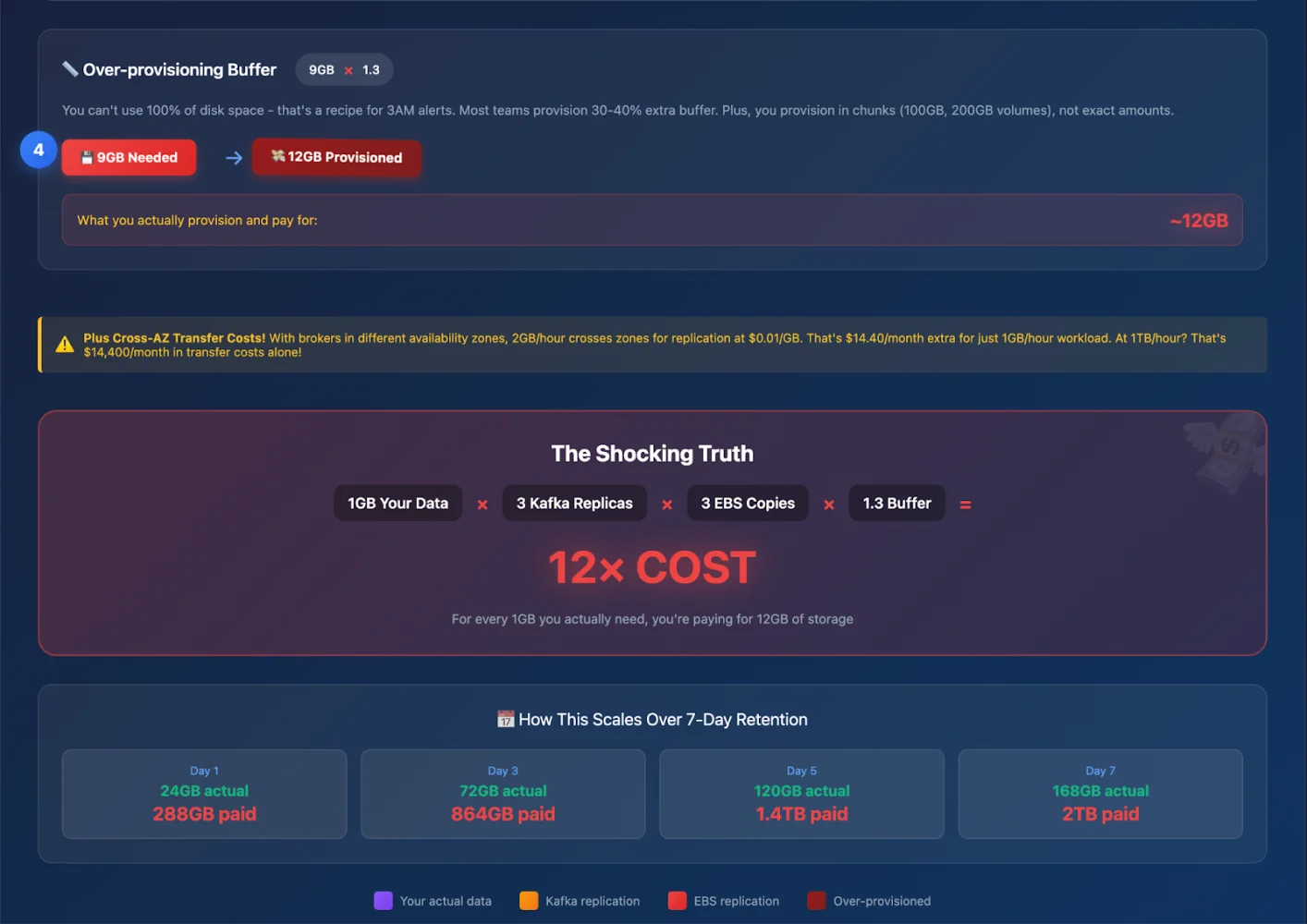
Here's what this architecture actually costs us:
-
9x data redundancy (yes, you read that right – 3x Kafka replication × 3x EBS replication).
-
Partition reassignments that feel like watching paint dry.
-
Zero elasticity – try auto-scaling Kafka and watch your weekend disappear.
-
Cross-AZ traffic bills that make our CFO cry 🥹🫣😀
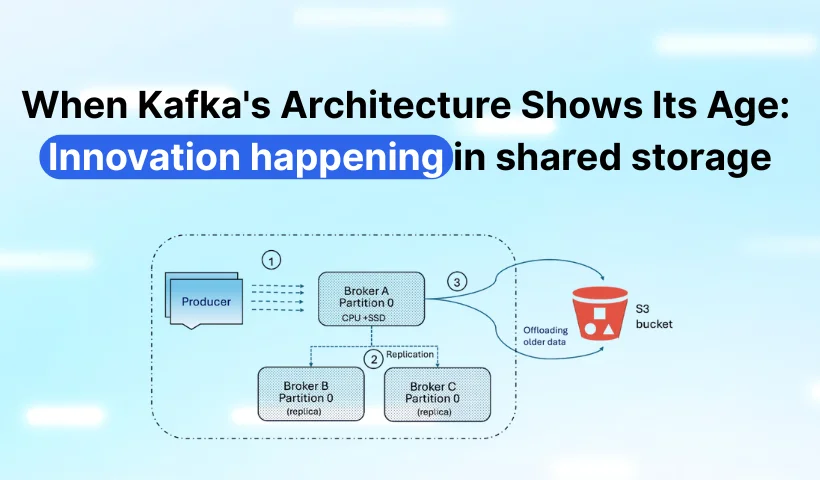
Operational cost of the Kafka: Shared-nothing architecture
Let me tell you a story that perfectly captures Kafka's cost problem.
Imagine you're running a small e-commerce site. You're ingesting just 1GB of data per hour – user clicks, orders, inventory updates. Nothing crazy. In the old days, you'd store this on a single server and call it a day. But this is 2026, and you need high availability, so you deploy Kafka.
Here's where the shared-nothing architecture kicks you in the wallet.
What "Shared-Nothing" Really Means
In Kafka's world, "shared-nothing" means each broker is like a paranoid hermit. They don't share anything – not storage, not data, nothing. Each broker has its own local disks, manages its own data, and essentially treats other brokers like strangers it happens to work with.
Think of it like three roommates who refuse to share a Netflix account. Instead, each one pays for their own subscription, downloads the same shows to their own devices, and guards their password jealously. Sounds expensive? That's because it is.
The Triple (or Worse) Whammy 🥴
Now, here's where it gets painful.
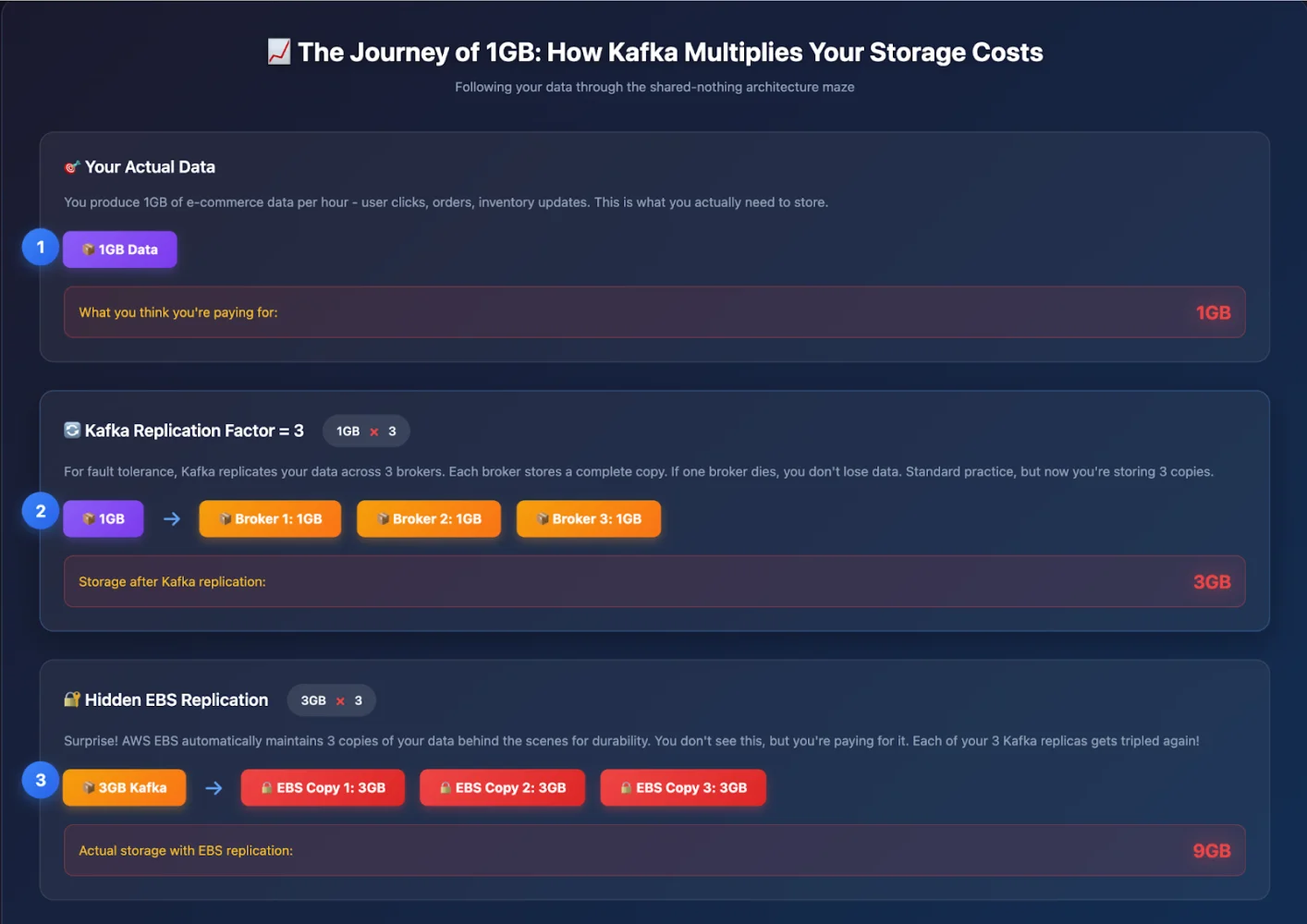
Observe the above diagram very carefully.
Now let’s follow your 1GB/hour of data through Kafka’s replication model:
-
Hour 1: Your app produces 1GB of data.
-
Kafka replication (RF=3): That 1GB becomes 3GB across brokers.
-
EBS replication: Each of those 3GB copies is triplicated by AWS → 9GB.
-
Headroom: Add 30–40% buffer to avoid midnight alerts → ~12GB provisioned.
So for every 1GB you ingest, you pay for ~12GB.
A Week in the Life of Your Data (and Your Bill)
With 7-day retention (a common setting):
-
Day 1: 24GB actual data → 288GB provisioned.
-
Day 3: 72GB actual data → 864GB provisioned.
-
Day 7: 168GB actual data → ~2,016GB provisioned.
And the kicker? Even if you’re only consuming the last hour of data, you’re still paying to store and replicate all seven days.
This is just a rough calculation for demonstrating the high cost of Apache Kafka.
The Cross-AZ Cherry on Top 🍒
Replication across AZs makes things worse:
At 1 GB/hour ingest (RF=3):
-
2 GB/hour crosses AZs.
-
~1,460 GB/month → ≈$29/month at ~$0.02/GB (two charges of ~$0.01/GB per direction).
At 100 MB/s ingest (RF=3):
-
Replication adds 200 MB/s cross-AZ.
-
Producers writing to leaders in other AZs add another ~67 MB/s.
-
Total ≈ 267 MB/s → 700,800 GB/month.
-
→ ~$14,000/month in cross-AZ replication + producer traffic.
-
If consumers fetch across AZs too, that climbs to ~$17,500/month.
The Bottom Line
Shared-nothing made perfect sense in 2011. You had physical servers, local disks, and SANs that couldn’t match local disk performance.
But in the cloud? You’re paying for the same data 12 times over—plus network charges, plus the operational pain of managing all those disks. It’s like buying DVDs in the age of Netflix 😂—and then buying three copies of each, storing them in three houses, and hiring someone to keep them in sync.
Today things are different. S3 has become the de facto standard for cloud storage—cheap, durable, and available everywhere. That’s why entire categories of systems—databases, warehouses, and now streaming platforms—are being redesigned around shared-storage architectures.
Projects like AutoMQ, Aiven, and Redpanda etc, embrace this shift by decoupling storage from compute. Instead of endlessly replicating across brokers, they use S3 for durability and availability, cutting both infrastructure duplication and cross-AZ network costs.
Each is an attempt to cut duplication, shrink cross-AZ costs, and embrace cloud-native design. Most of the new-age Apache Kafka projects that are trying to bring costs down are actually following either of two approaches.
-
Some pushes Kafka toward a fully shared-storage model—brokers become stateless, storage lives in S3.
-
While others take a tiered storage approach—older segments are offloaded to S3/GCS, reducing local disk usage but still keeping a hot tier.
Of course, running Kafka on S3 brings its own challenges—latency, consistency, metadata handling. We’ll explore these in detail, focusing on how open the new project and open source like AutoMQ are trying to tackle them efficiently.
There has to be a better way, right?
(Spoiler: there is—and that’s where our deep dive begins…)
Proposal of Tiered Storage in Kafka
The Kafka community has been actively discussing and developing tiered storage (see KIP-405).
Before I share why I think this design might be a trap, let’s first explain it in plain terms.
Traditionally, Kafka brokers store all data locally on their disks. That’s fast, but costly and hard to scale — if you run out of space, you add more brokers or bigger disks, which ties storage growth to compute growth.
Tiered storage breaks this pattern by splitting data into two layers:
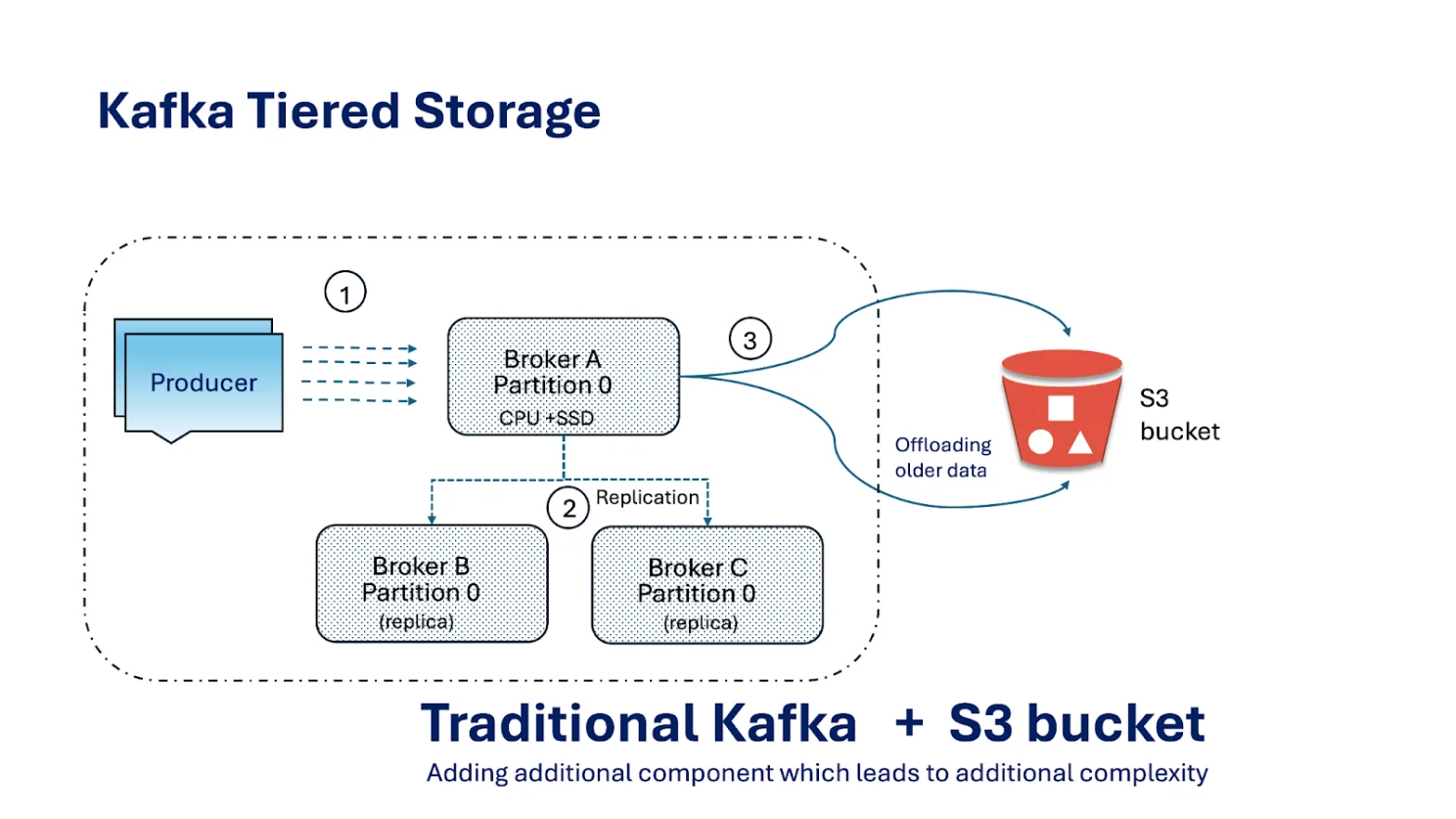
Key aspects of Kafka Tiered Storage:
Hot/Local Tier:
- This tier resides on the local disks of the Kafka brokers. It stores the most recent data and is optimised for high-throughput writes and low-latency reads.
Cold/Remote Tier:
- This tier utilises a separate, typically cheaper and more scalable, storage system. Older data segments are asynchronously uploaded to this remote tier, freeing up local disk space on the brokers.
Data Movement:
- Only closed log segments are uploaded. Consumers can read from either tier; if the data isn’t on the broker, Kafka fetches it from the remote tier
Benefits touted by Tiered Storage
-
Lower cost: old data sits on S3/GCS instead of expensive broker disks.
-
Elasticity: storage and compute scale more independently.
-
Operational perks: less local data means faster broker restarts and recoveries.
On paper, it looks like a neat compromise: keep hot data close, offload cold data far.
Why Tiered Storage Still Leaves You Stuck
Now here’s where I share my view: I think tiered storage is a band-aid on a deeper problem .
Remember our 1 GB of e-commerce data that ballooned into ~12 GB? Tiered storage doesn’t fix that foundation. It’s like renovating the kitchen when the house’s foundation is cracking .
Let’s break it down.
Problem #1: The “Hot Tail” That Won’t Let Go
Kafka must keep the active segment on local disk . Always. It cannot be offloaded until the segment is “closed.”
That segment might be 1 GB… or 50 GB during Black Friday traffic. Multiply by RF=3, and suddenly you’ve got 150 GB sitting on expensive local disks for a single partition .
So yes, old data moves off, but the hot tail stays — and it can be massive.
Problem #2: Partition Reassignments Still Hurt
Adding brokers? Rebalancing partitions? Tiered storage only helps a little.
Example:
-
Without tiered storage: maybe you need to move 500 GB → 12 hours of pain.
-
With tiered storage: maybe only 100 GB of hot data moves → 2–3 hours of pain.
Better, sure. But if your site is melting during checkout, waiting hours for data to shuffle is still unacceptable. The scaling bottleneck remains.
Problem #3: The Hidden Complexity Tax
My engineering mind summed it up for me perfectly :)
“Now I manage two storage systems instead of one 😂😣. I debug local disk issues and S3 issues. Twice the metrics. Twice the alerts. Sometimes data even gets stuck between tiers.”
Instead of simplification, you get more moving parts. It’s like cleaning your messy desk by… buying a second desk.
My Takeaway
Tiered storage is clever, and it does reduce storage costs. But it doesn’t solve the fundamental coupling between compute and storage in Kafka’s shared-nothing design. You still pay the price in hot-tier costs, scaling friction, and operational complexity.
The real question isn’t: “How do we make broker disks cheaper?”
It’s: “Do brokers need to own disks at all?”
That’s where projects like AutoMQ push further — making brokers stateless and letting shared cloud storage handle durability.
Okay... but brokers are still stateful and not cloud native
The more I worked with Kafka, the more I began to question its core design assumptions.
If we look at the drawbacks so far, they all point to one missing ingredient: true cloud nativeness .
Even with tiered storage, Kafka brokers are still stateful . Storage and compute remain tightly coupled. Scaling or recovering brokers still involves shuffling data around.
To make Kafka truly cloud-native, the community began exploring Diskless Kafka (see KIP-1150), where compute and storage are fully disaggregated.
Think of it like Google Docs: instead of saving files to our own hard drives, everything lives in a shared cloud space. Brokers no longer “own” data. They just connect to the shared storage.
Imagine this world:
-
No local disks to manage.
-
No panic when a broker crashes — because no data is lost.
-
No painful partition reassignments.
-
Add a broker? It just plugs in.
-
Remove one? No problem — the data is safe elsewhere.
Wouldn’t that solve half the headaches we’ve talked about? Think, think and think, these are just my thoughts :). You might come up with much better than mine. Let me know your thoughts in the comment section, or I'm always ready for a discussion through personal message.
Diskless Kafka is the cure.
Even though diskless Kafka isn’t available in Apache Kafka yet, open-source projects like AutoMQ have already implemented it — and what I personally love is that AutoMQ is 100% compatible with Kafka APIs .
Back in 2023, the AutoMQ team set out to make Kafka truly cloud-native. They recognised early that Amazon S3 (and S3-compatible object stores) were becoming the de facto standard for durable cloud storage.
AutoMQ is 100% Kafka-compatible but reinvents the storage layer:
-
All log segments live in cloud object storage (e.g., S3).
-
Brokers become lightweight and stateless , acting as protocol routers.
-
The source of truth is no longer broker disks but the shared storage.
Why reinvent storage when cloud providers already offer virtually infinite capacity, multi-AZ replication, and “11 nines” durability ? AutoMQ leans on S3 (or compatible stores) to handle durability, while brokers just move data in and out.
The benefits are big:
-
Scale easily: Compute and storage scale independently. Add brokers for throughput, and storage grows automatically in the cloud.
-
Fast rebalancing: No data shuffle. Adding/removing brokers just means leader reassignments.
-
Stronger durability: Cloud object storage provides redundancy without maintaining 3× replicas on brokers.
-
Simpler ops: Brokers become disposable. If one dies, spin up another; no replica syncing required.
In other words, brokers become cattle, not pets.
The metaphor I like best? Think of Google Docs. Instead of saving files to your “C:” drive, everything lives on a shared drive. Brokers just provide access — the data itself is always safe in the cloud.
Instead of each broker hoarding data on its own disks, AutoMQ envisioned shared storage : all Kafka data living in a common cloud repository that any broker could access. This wasn’t just a wild theory—AutoMQ actually implemented it (as a fully Kafka-compatible fork), effectively decoupling compute and storage in Kafka’s architecture.
In essence, they decided to stand on the shoulders of giants (cloud providers) rather than reinvent the wheel. Why build a complex storage system from scratch when services like S3 offer virtually infinite capacity, multi-AZ replication, and rock-solid durability out of the box?
To understand what AutoMQ did, imagine Kafka running like Google Docs : brokers no longer save data to local “C:” drives; they write to a shared cloud drive that everyone uses. Concretely, AutoMQ’s brokers are stateless and simply act as lightweight traffic cops, speaking the Kafka protocol and routing data to/from storage. The Kafka log segments aren’t on the broker’s disk anymore – they’re in cloud object storage (S3) as the source of truth. This design brings some huge benefits.
For one, durability is vastly improved – you’re leveraging S3’s built-in replication and reliability instead of maintaining 3 copies on different brokers. Costs drop, too, because object storage is much cheaper at scale than provisioning tons of local SSDs (especially when factoring in 3x replication on those disks). And scaling? It becomes almost plug-and-play.
Need more throughput? Add more broker instances (compute) and point them at the same storage; there’s no massive data shuffle to rebalance partitions. Brokers can come and go like cattle, not pets – if one dies, a new one can boot up and serve data immediately since the data is safely stored elsewhere. It’s the kind of cloudy elasticity Kafka always struggled with before. As one Kafka cloud architect put it, “storage grows automatically in the cloud; brokers just bring the muscle to move data in and out” .
Finally, let's summarise the advantages brought by the AutoMQ Diskless architecture.
Benefits of a Diskless Architecture
-
Scale easily: Compute (brokers) and storage grow separately. Add brokers for throughput, and storage grows automatically in the cloud. You don’t need to overprovision disk space anymore. Pay only for what you use 🙂
-
Fast rebalancing: No partition data to shuffle. Adding/removing brokers just means reassigning leaders. Almost instant.
-
Stronger durability: Object storage offers “11 nines” durability, far better than broker replication.
-
Simple ops: Broker crashes don’t matter. Just replace it. No data recovery or replica syncing needed.
The Latency Challenge
On paper, diskless Kafka sounds perfect. But there’s a catch: object storage brings latency .
Kafka is prized for its low latency, and writing directly to S3 or GCS introduces delays and API overhead.
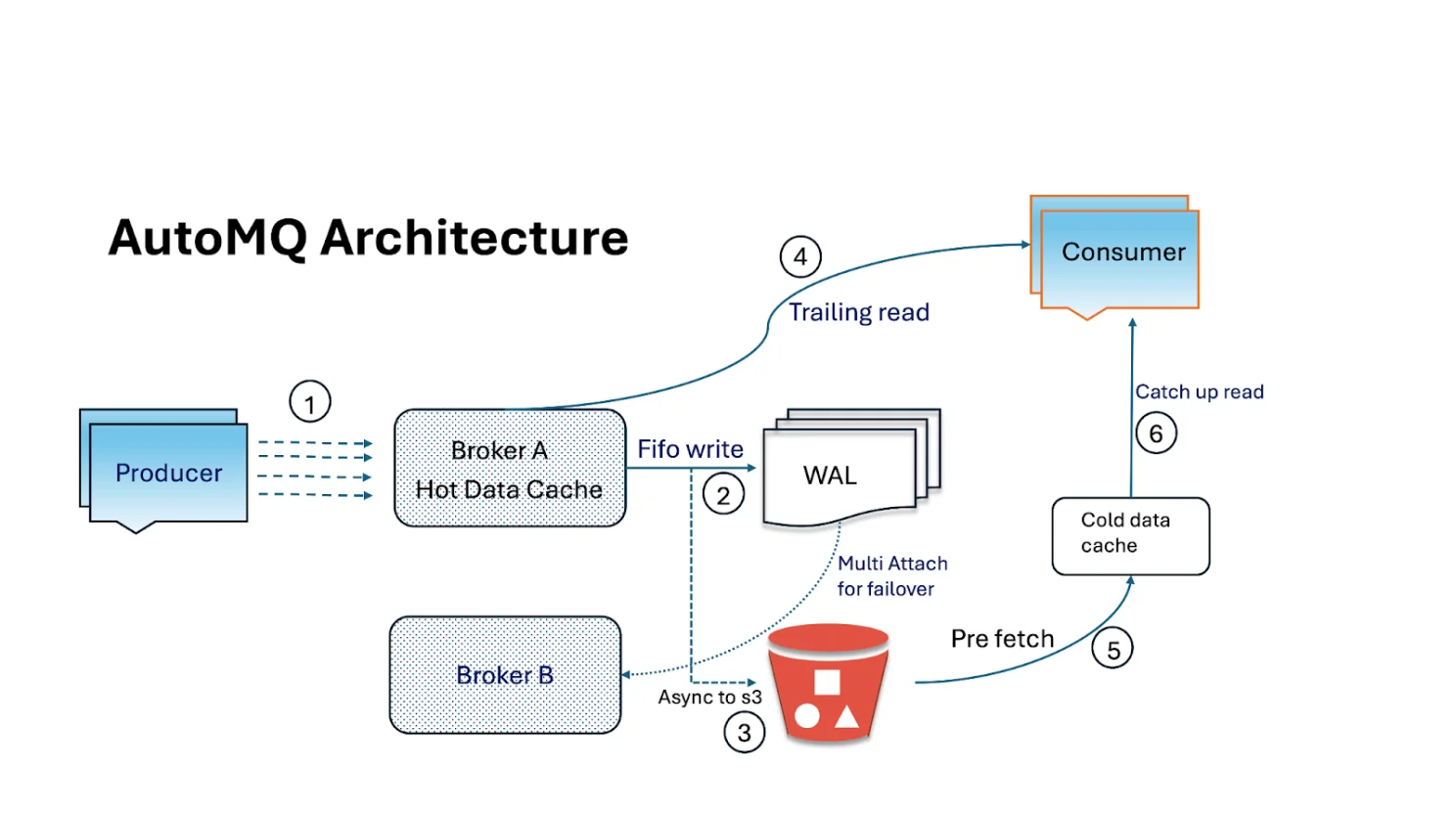
Here’s where AutoMQ made a smart move: they added a Write-Ahead Log (WAL) abstraction. Messages are first appended to a small, durable WAL. AutoMQ supports multiple WAL backends — including S3 WAL (the default for AutoMQ Open Source) and block storage options like EBS/NVMe for lower latency — while long-term durability is handled by S3. This reduces latency while still keeping brokers diskless.
Can we improve this further?
There are still use cases where latency is king — financial systems, high-frequency trading, low-latency analytics. For these, even AutoMQ’s WAL approach needs further innovation.
AutoMQ has hinted at proprietary/commercial solutions that go further:
-
Direct-to-WAL writes: Every message goes to a durable cloud-backed WAL.
-
Brokers then serve reads from cache or memory.
-
WAL volumes are small (e.g., 10 GB) and can be quickly attached to another broker if one fails.
How is this different from Kafka’s tiered storage?
-
Tiered storage: Data is written to broker disks first, replicated across brokers, and only later offloaded to S3.
-
AutoMQ diskless: No broker disks at all. Data durability comes from the cloud storage layer itself. No replication shuffle required.
If a broker crashes, its WAL volume is simply attached to a new broker, which continues right where the old one left off. Storage outlives compute.
That’s a huge mindset shift: compute is disposable, storage is stable .
There are some use cases where latency plays a crucial role. Because of this, the above solution might not be a perfect fit, which requires further improvement. Digging further, I found they also offer a solution for this 🤯 But it seems like it is an AutoMQ proprietary/commercial offering.
This solution might look a little overwhelmed, but it shows true engineering brilliance. It is a next-generation Diskless Kafka on S3.
Of course, S3 is “slow” compared to SSDs/Local disk . Also, the efficiency of writing data to cloud storage (s3) has to be improved to avoid API overhead.
Isn’t this just like Kafka’s tiered storage?
That was my first reaction too: “Wait, isn’t this the same as tiered storage, where Kafka offloads data to S3?”
Not really. Here’s the difference:
-
In Kafka with tiered storage , data still has to hit the broker’s local disk first. Replication between brokers (ISR) is still mandatory. Only after that do older segments get offloaded to S3.
-
In AutoMQ , there’s no local disk in the picture at all. Data goes directly to the WAL in cloud-backed storage. Replication isn’t needed because the cloud volume is already durable and redundant.
So it’s not just an optimisation. It’s a completely different design.
But what if a broker crashes?
Good question, this was the next “aha” moment for us.
In Kafka, when a broker dies, partitions need to be reassigned and replicas resynced. Painful.
In AutoMQ, it works differently:
-
Each broker is just a compute instance attached to a durable cloud volume (EBS or NVMe).
-
Let’s say Broker A is writing to its WAL (EBS) volume. Suddenly, Broker A crashes.
-
No problem. The data’s still safe in the WAL volume.
-
The cluster quickly attaches that same volume to Broker B , which picks up right where Broker A left off.
-
No data loss, no replication shuffle, no waiting around.
Basically, in AutoMQ, the storage outlives the broker . Compute is disposable, storage is stable.
That’s a huge mindset shift from Kafka’s model. Instead of tightly coupling compute and storage, AutoMQ cleanly separates them, and that’s what makes the design so interesting. If you want to deep dive further, you can check their docs.
Final Thoughts
If you’ve read this far, thank you for sticking with me! You’ve made it this far — thank you 🙌
The idea we’ve been exploring is simple but powerful:
What if cloud storage replaced local disks as the foundation for Kafka-like systems?
This shift cuts away so much operational pain:
-
No more broker reassignments.
-
No more frantic disk alerts.
-
Scaling becomes plug-and-play.
It’s exciting to see projects like AutoMQ push in this direction, while staying compatible with Kafka APIs and tooling.


