


.png)
Introduction
There are many open-source products compatible with the Kafka protocol, such as Redpanda and Kafka on Pulsar. Some of these products rebuild Kafka from scratch, while others adapt the protocol based on existing products. Currently, the Kafka protocol includes 113 ErrorCodes and 68 APIs, with just the Fetch API having 15 versions. Achieving 100% compatibility with the Kafka protocol and semantics is extremely challenging. Moreover, as Apache Kafka® evolves, maintaining continuous compatibility with the Kafka protocol is also a significant challenge.
The compatibility of the Kafka protocol and semantics is a crucial consideration for users choosing Kafka products. Therefore, the premise of AutoMQ for Kafka (referred to as AutoMQ Kafka) architectural design is to ensure 100% compatibility with Apache Kafka® protocol and semantics and to continuously align with and follow Apache Kafka®.
100% API Compatibility
Apache Kafka has undergone over 10 years of development, with contributions from more than 1,000 contributors, resulting in 1019 KIPs. As of February 23, 2024 (commit 06392f7ae2), the entire codebase contains 885,981 lines of code, encompassing a wealth of features, optimizations, and fixes. Building an API-compatible and semantically equivalent Kafka from scratch would not only require substantial development effort but also be highly error-prone. The Apache Kafka architecture consists of a compute layer and a storage layer:
Compute Layer: Comprising 98% of the total code, this layer handles Kafka's API protocols and features, with the primary overhead being the CPU resources consumed for message processing. Thanks to Apache Kafka's efficient message batching and API request batching, a dual-core CPU can support 1GB/s throughput, minimizing CPU consumption to its limits.
Storage Layer: Making up 1.97% of the total code, with only 17,532 lines of code, this layer ensures the durable storage of messages. As a stream processing pipeline, Apache Kafka stores large volumes of data long-term, with the majority of Kafka cluster costs stemming from data storage expenses and the costs associated with integrated storage-compute deployments.
AutoMQ Kafka aims to reduce Kafka's costs by 10x, primarily focusing on cloud-native optimizations of the storage layer. Thus, the core strategy of AutoMQ Kafka is to refactor Apache Kafka for cloud-native environments through a storage-compute separation architecture:
Reuse 98% of Apache Kafka's compute layer code to ensure API protocol and semantic compatibility and feature alignment.
Replace the storage layer with cloud-native storage services, achieving serverless Kafka and 10x cost reduction.
Apache Kafka
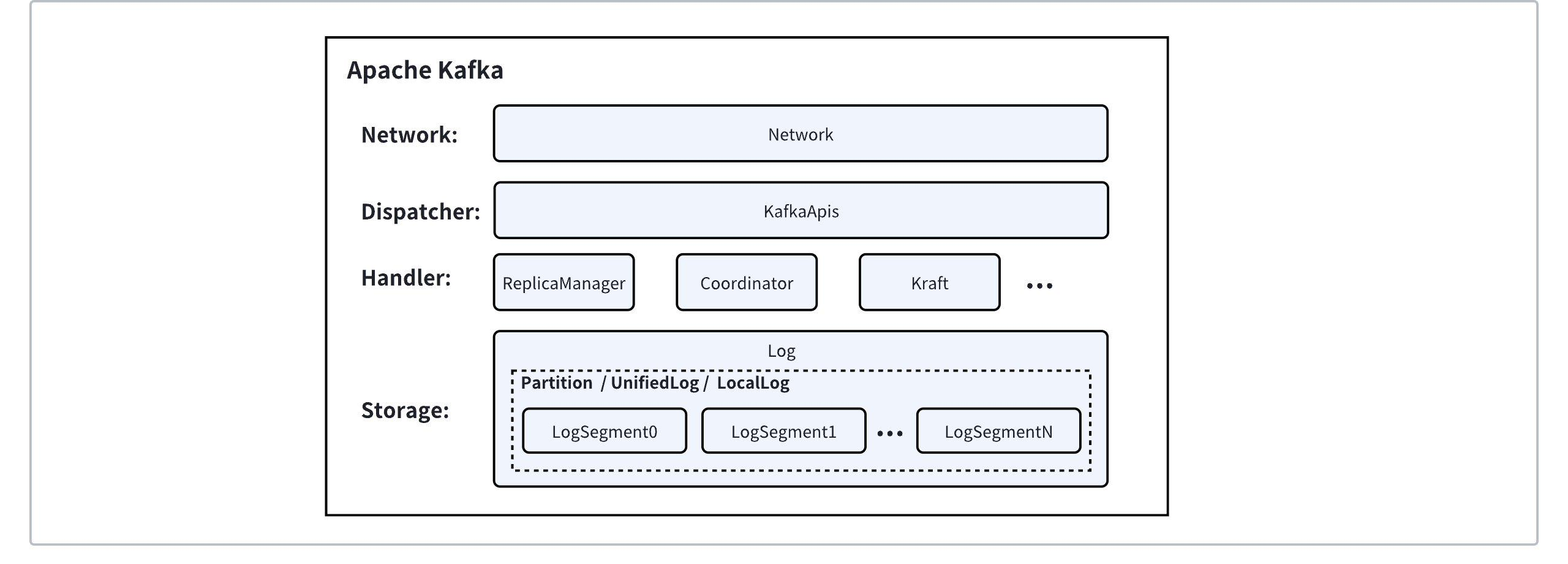
Before introducing the 100% API compatibility solution, let's review Apache Kafka's module hierarchy. Apache Kafka processes traffic from north to south as follows:
Network Layer: Responsible for managing connections, decoding network packets from clients into requests, and encoding responses into network packets to send back to clients;
Distribution Layer: After receiving a request, KafkaApis dispatches the request to specific business logic handling modules based on the ApiKey of the request;
Business Logic Layer: Split into finer sub-modules to handle different business logic. ReplicaManager is responsible for message sending and receiving and partition management; Coordinator is responsible for consumer management and transactional messages; Kraft is responsible for cluster metadata;
Storage Layer: Responsible for the high-reliability storage of data, providing the Partition abstraction to the business logic layer. It is divided into multiple levels from top to bottom: UnifiedLog ensures high-reliability data through ISR multi-replica replication; LocalLog handles local data storage, offering an "infinite" stream storage abstraction; LogSegment, the smallest storage unit in Kafka, splits LocalLog into data segments and maps them to corresponding physical files;
Using Apache Kafka® to process a Produce message as an example:
The Network Layer parses the network packet into a ProduceRequest;
Then KafkaApis dispatches the request to ReplicaManager based on ApiKey.PRODUCE;
ReplicaManager#appendRecords finds the corresponding Partition;
Partition#appendRecordsToLeader ultimately calls LocalLog, which writes the messages to the Active Segment.
LogSegment persists the messages to the data file and constructs corresponding indexes such as index, timeindex, and txnindex.
Other business logic layer modules, such as the transaction Coordinator, Consumer Group Coordinator, and Kraft metadata, are also essentially built around the Partition (Log).
AutoMQ Kafka
As mentioned earlier, AutoMQ Kafka adopts a storage-compute separation architecture. In the storage layer, AutoMQ Kafka abstracts S3Stream stream storage to replace Apache Kafka's local Log storage. The storage layer exposes the same Partition abstraction upwards, allowing the upper-layer Kraft metadata management, Coordinator, ReplicaManager, KafkaApis, and other modules to reuse the original code logic. By reusing the original logic at the storage layer, AutoMQ Kafka not only achieves 100% protocol and semantic compatibility effortlessly but also continuously follows the latest features and bug fixes of Apache Kafka.
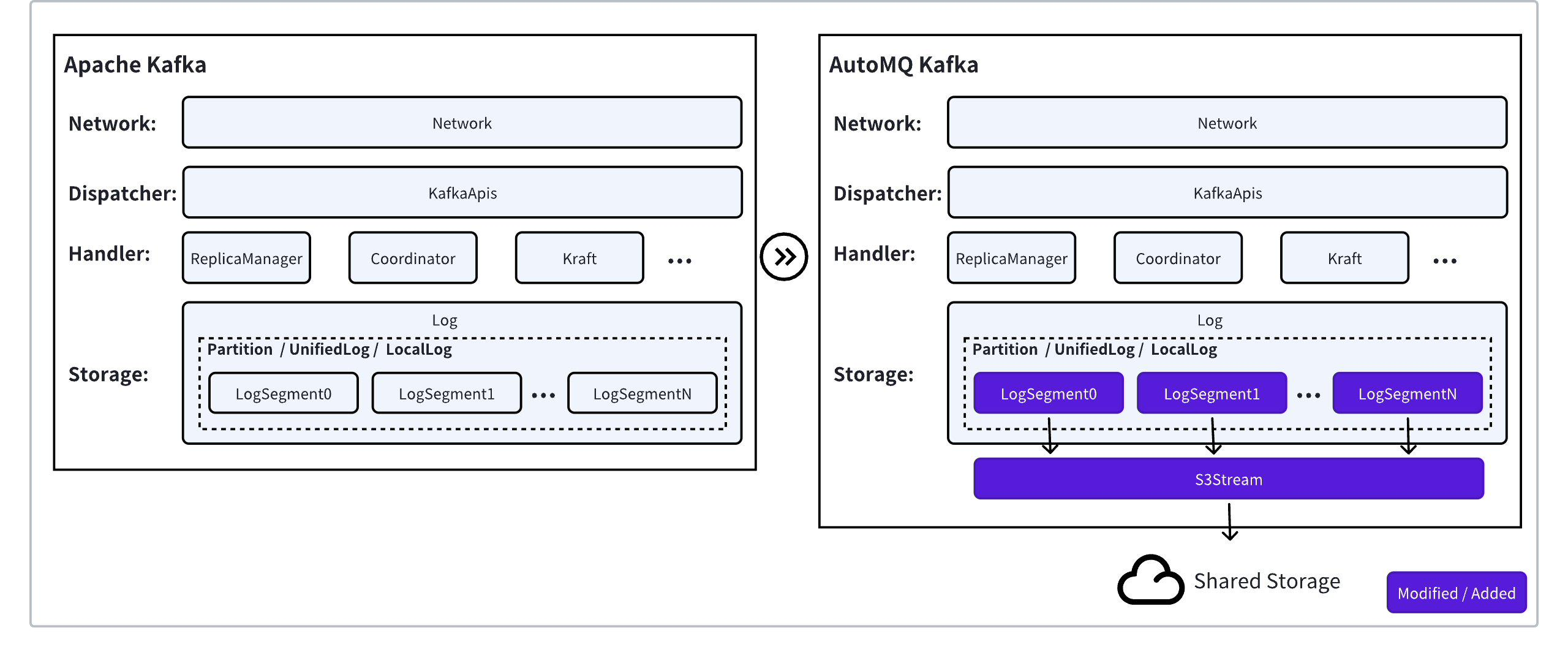
S3Stream
S3Stream is built on cloud disks and object storage, providing a low-latency, high-throughput, and cost-effective stream abstraction. At the API level, the core methods append and fetch provide stream writing and reading, respectively. Compared to Kafka's Log, it is more straightforward, lacking features such as transaction index, timestamp index, and compaction. S3Stream focuses more on stream storage without concerning itself with upper-layer business logic.
interface Stream {
CompletableFuture<AppendResult> append(AppendContext context, RecordBatch recordBatch);
CompletableFuture<FetchResult> fetch(FetchContext context, long startOffset, long endOffset, int maxBytesHint);
CompletableFuture<Void> trim(long newStartOffset);
// others
}
interface RecordBatch {
// records count, it's usually equal to Kafka RecordBatch.count
// and it also could be used as offset padding for compacted topic
int count();
ByteBuffer rawPayload();
}
Since S3Stream's capabilities do not align with Kafka's Log, how does AutoMQ Kafka achieve storage layer replacement? This is related to AutoMQ Kafka's ingenious storage aspect.
Storage Aspect
Before introducing AutoMQ Kafka's storage aspect, let's briefly explore the compaction logic of Apache Kafka's Compact Topic:
LogCleaner periodically compacts partitions of a Compact Topic.
It first groups the inactive segments of a partition.
Then, it scans the valid data within each group and writes it into a new segment, Segment.cleaned.
Finally, it replaces the old segment with the new segment, completing the compaction process.
Although Kafka exposes a continuous stream abstraction at the business logic layer through partitions, the internal compacting logic operates with segments as the smallest storage unit. Similarly, Kafka's log recovery, transaction index, timestamp index, and reading operations are all segment-based. Therefore, AutoMQ Kafka's storage facet is also centered around segments. By implementing segment semantics, the upper layers of LocalLog, LogCleaner, and Partition logic can be reused, ensuring consistency with Apache Kafka's storage logic.
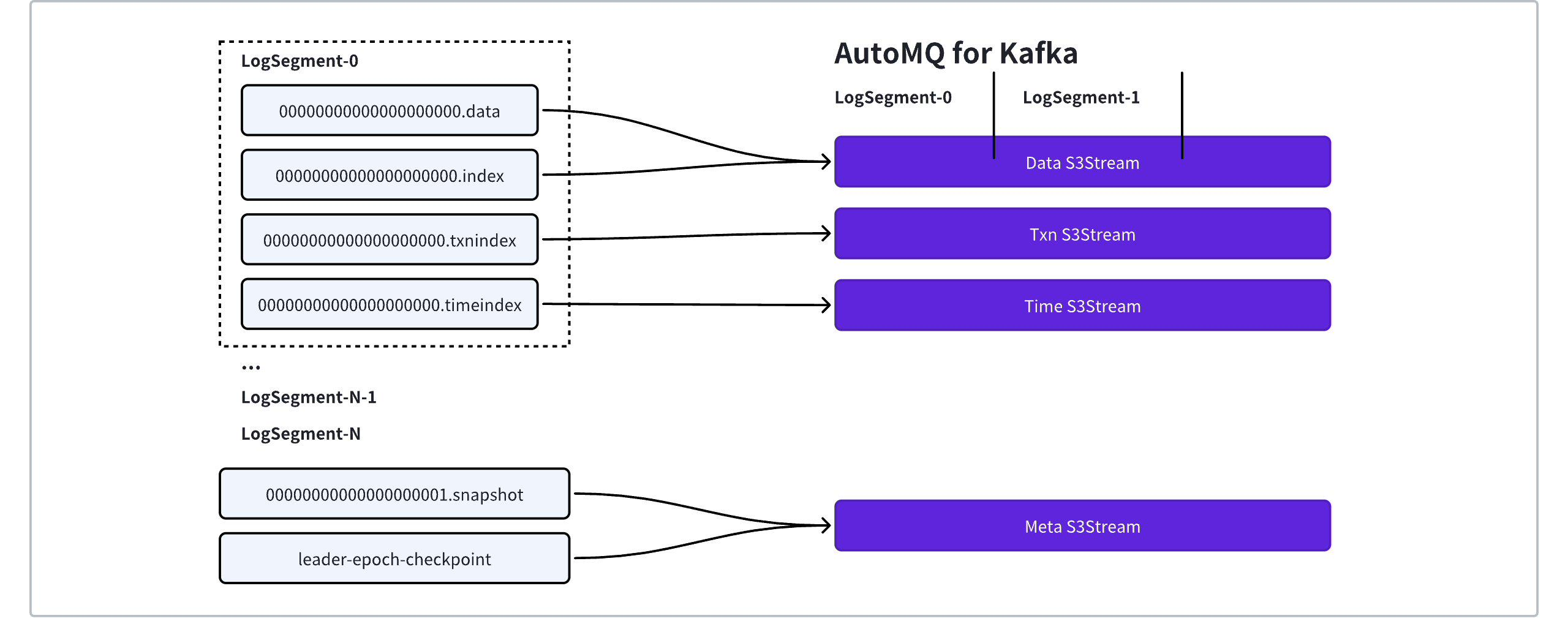
In Apache Kafka, a partition consists of two types of data:
Partition-level data includes producer idempotence snapshot data xxx.snapshot, leader epoch information (leader-epoch-checkpoint), and other metadata.
Segment-level data includes data files xxx.data, sparse index files xxx.index, transaction index files xxx.tnxindex, and time index files xxx.timeindex.
AutoMQ Kafka aims to make Kafka stateless by offloading these files' data to S3Stream:
Meta: Meta S3Stream provides a KV-like semantic to store metadata at the Partition level. Apache Kafka can scan the file system directory tree to list Segments under a Partition. In AutoMQ Kafka, Meta S3Stream uses ElasticLogMeta to record the Segment list and the mapping between Segments and Streams.
Data: The S3Stream API already provides the capability to query data based on logical offsets. Thus, xxx.data and xxx.index can be replaced together by Data S3Stream.
Txn/Time: These are equivalently replaced by the original xxx.tnxindex and xxx.timeindex.
A Segment is a bounded data chunk that rolls over based on size and time. If each file under a Segment is mapped to a Stream, the number of Streams would grow rapidly. Therefore, AutoMQ Kafka splits the Stream logic into Slices mapped to Segment files, limiting a Partition's fixed overhead to 3-7 Streams. The final mapping expression is similar to:
{
"streamMap": {
"log": 100, // stream id
"time": 101,
...
}
"segments": [
{
"baseOffset": 0, // segment base offset
"streamSuffix": "", // if the suffix is .cleaned, means the segment is created from compaction, and the under data stream key is log.cleaned
"log": { "start": 0, "end": 2 }, // stream slice
"time": { "start": 0, "end": 12 },
...
},
{
"baseOffset": 2, // segment base offset
"streamSuffix": "",
"log": { "start": 2, "end": 5 },
...
},
{
"baseOffset": 5, // segment base offset
"streamSuffix": "",
"log": { "start": 5 "end": -1 }, // end = -1 represent it's the active segment
...
},
]
}
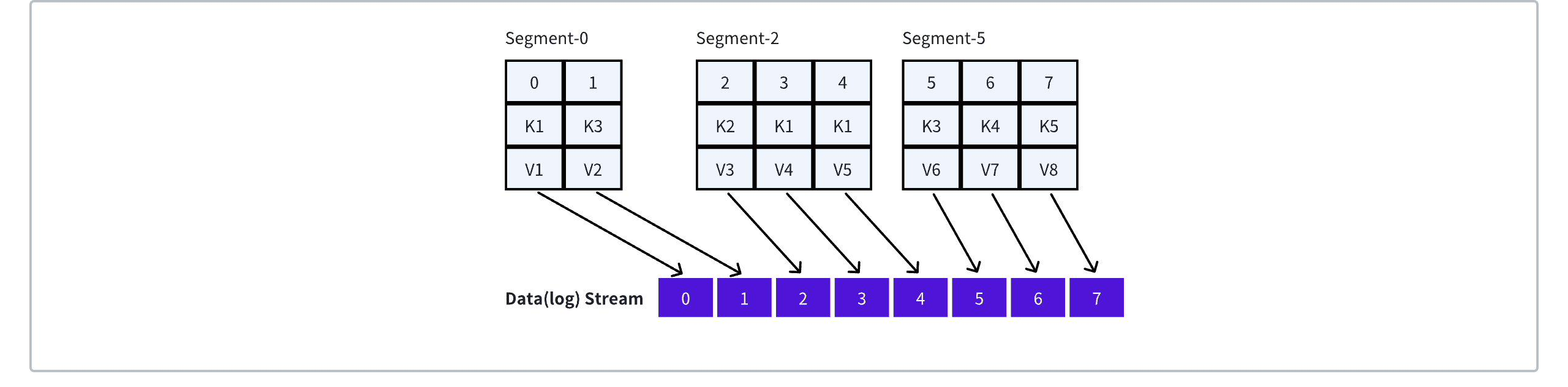
For example, consider the mapping relationship mentioned above: there are three Segments under the Partition: Segment-0, Segment-2, and Segment-5.
Segment-0 holds messages in the [0, 2) range, and the data is mapped to the Stream in the same range [0, 2). Reading data in the [0, 2) range of the Partition maps to reading DataStream#fetch(0, 2).
Among these, Segment-5 is the active Segment, and the baseOffset for new data written to the Partition is allocated as 8.
In the previously mentioned Compact Topic scenario, assume Segment-0 and Segment-2 will be compacted into Segment-0.cleaned. The baseOffset of the Segment is 0, mapped to the [0, 5) range in the Data(log.cleaned) Stream. To ensure continuous addressing in the Stream, the message with offset = 1 in Kafka will be mapped to RecordBatch{offset=0, count=2}, where count=2 is used to fill the gap created by the compaction of offset = 0. Similarly, the message with offset = 2 in Kafka is mapped to RecordBatch{offset=2, count=1}, and the message with offset = 4 is mapped to RecordBatch{offset=3, count=2}.
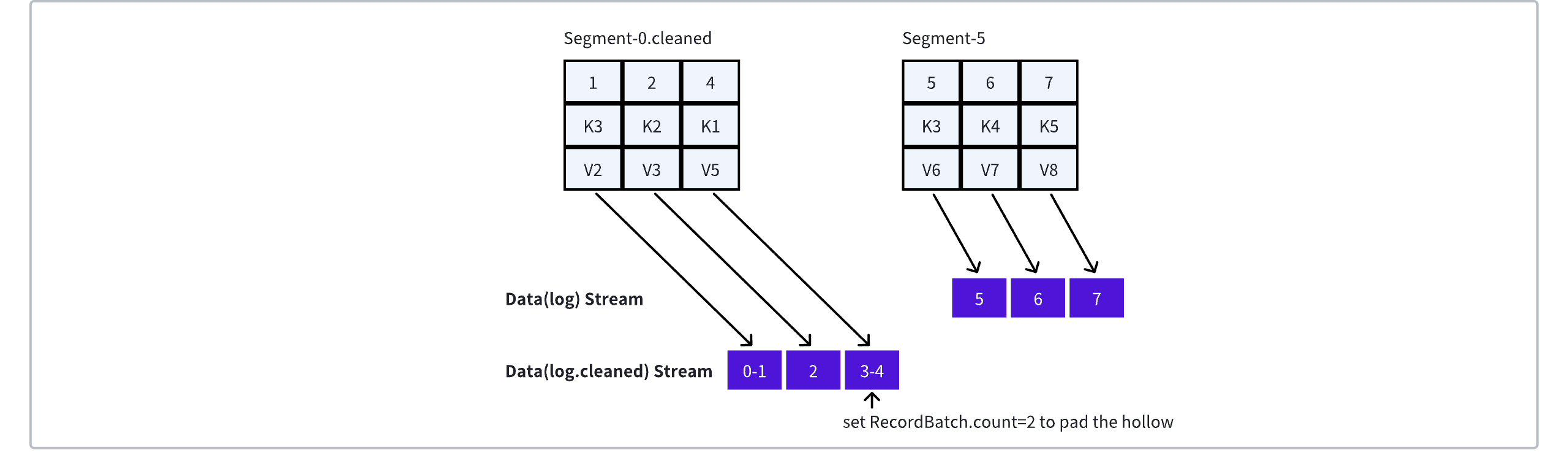
Segment0.cleaned replaces Segment-0/2 and the original Segment-5 to form a new list of Segments, ultimately generating the following ElasticLogMeta:
{
"streamMap": {
"log": 100, // stream id
"time": 101,
"log.cleaned": 102,
...
}
"segments": [
{
"baseOffset": 0, // segment base offset
"streamSuffix": ".cleaned", // if the suffix is .cleaned, means the segment is created from compaction, and the under data stream key is log.cleaned
"log": { "start": 0, "end": 5 }, // stream slice
...
},
{
"baseOffset": 5, // segment base offset
"streamSuffix": "",
"log": { "start": 5, "end": -1 }, // end = -1 represent it's the active segment
...
},
]
}
Through this mapping method, the conversion from Kafka's local storage files to the S3Stream is lightweight, reusing most of the storage layer logic except for the Segment, achieving semantic compatibility in the storage layer.
Quality Assurance
Besides achieving 100% API compatibility in theoretical architecture design, AutoMQ Kafka has also passed all 387 system test cases of Apache Kafka (Kraft mode). These test cases cover Kafka functionalities (message sending/receiving, consumer management, Topic Compaction, etc.), client compatibility (>= 0.9), operations (partition reassignment, rolling restart, etc.), and aspects of Stream and Connector testing, ensuring 100% protocol and semantic compatibility of AutoMQ Kafka from a practical perspective.
Future Plans
Thanks to the minimal storage layer modifications, the cost of merging and keeping up with Apache Kafka code is low for AutoMQ Kafka.
AutoMQ Kafka plans to merge Apache Kafka code in April 2024, upgrading the kernel from version 3.4.0 to 3.6.0.
In the future, AutoMQ Kafka plans to adopt a T+1 Month model for merging Apache Kafka® code, continuously tracking new features and stability fixes in Apache Kafka®.





