Intro
In today’s data-driven world, Apache Kafka has become an indispensable piece in organizations’ data infrastructure. From processing financial transactions and IoT data to powering user activity tracking and microservices communication, Kafka has become the first choice.
However, as organizations scale, upgrade infrastructure, or optimize costs, the need to migrate Kafka clusters inevitably arises. This could involve transitioning from on-premises deployments to managed cloud services, switching between cloud providers, upgrading to newer Kafka versions, or adopting a more efficient alternative solution.
Such migrations present a unique set of challenges that require a reliable Kafka migration solution to deal with. The core problem lies in Kafka’s fundamental role as a central nervous system for data: any disruption can have cascading effects on business continuity.
In this article, we first examine the typical approach of available Kafka migration tools and then explore a refreshing solution from AutoMQ that ensures the migration process can happen without downtime.
Why downtime
Traditional Kafka cluster synchronization tools, such as Kafka’s MirrorMaker 2, focus on replicating data to a separate, target cluster. To ensure no data is lost or processed out of order during the transition, the producers are typically required to stop producing new messages and wait for all remaining messages to settle on the new cluster. Only after that can the producer resume the new cluster. The consumers also don’t have more messages to consume during the waiting period for the producer.
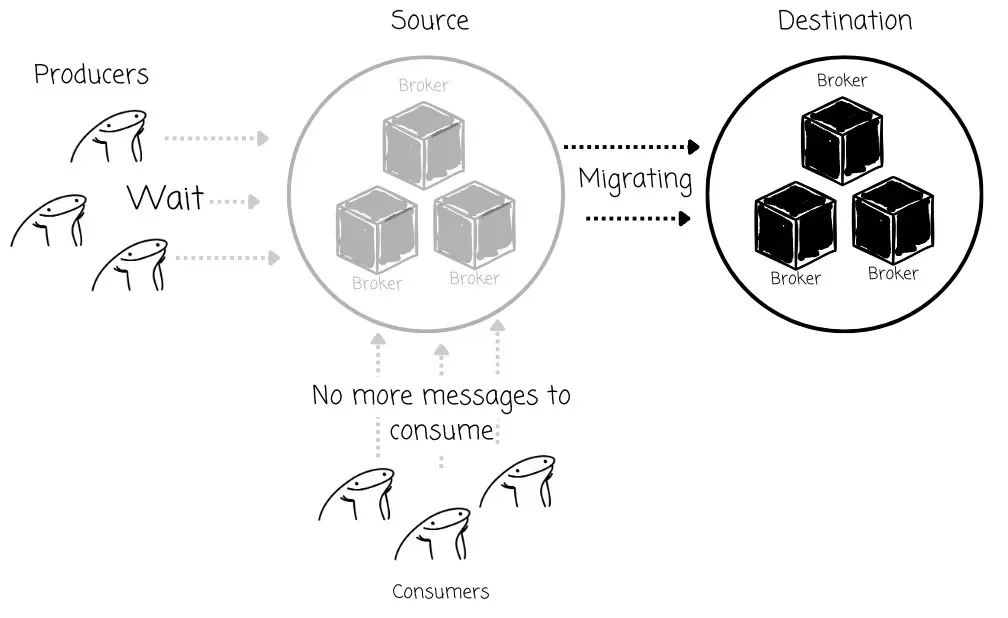
The most immediate impact is downtime for the applications reliant on the Kafka cluster. During the migration time, producers must stop sending messages; thus, consumers don’t have messages to consume. Furthermore, the “wait” period is inherently unpredictable and uncontrollable , as it depends on factors like the volume of data, network latency, and the processing speed of the synchronization tool.
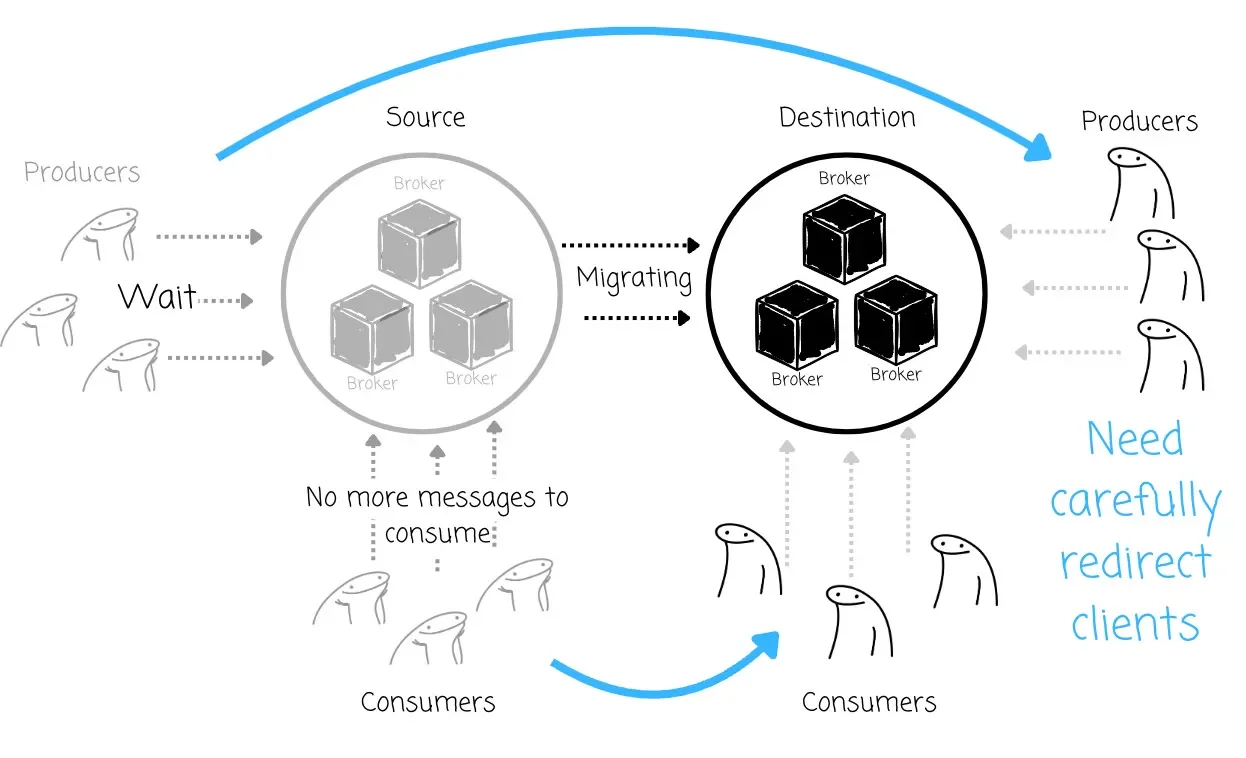
This process also introduces considerable operational complexity and manual overhead . Teams must carefully orchestrate the stopping and starting of numerous application instances, coordinate across different teams, and often manually verify data consistency before giving the “all clear” for restarts.
This increases the chances of human error and extends the maintenance window. The lack of a native client redirection mechanism introduces complexity that is prone to mistakes and makes the entire migration more risky than necessary, especially for large-scale Kafka deployments with numerous dependent services.
Moreover, the widely adopted MirrorMaker2 solution doesn’t preserve message offsets effectively because it relies on an imprecise offset mapping system rather than direct replication. This mapping is not maintained for every single record due to the high cost, which can lead to potential data reprocessing when consumers are migrated.
Furthermore, this offset translation doesn’t work for applications like Flink or Spark that manage offsets externally, making MirrorMaker2 unsuitable for seamlessly migrating all Kafka applications.
This means that solutions like MirrorMaker can’t ensure safe migration in every use case.
So, is there a solution that could address all the above problems?
AutoMQ Kafka linking
AutoMQ introduces Kafka Linking for the Kafka-AutoMQ migration purpose. It is the first zero-downtime Kafka migration solution in the industry while ensuring message offset preservation. It was built with two key principles in mind: dual write and rolling upgrade.
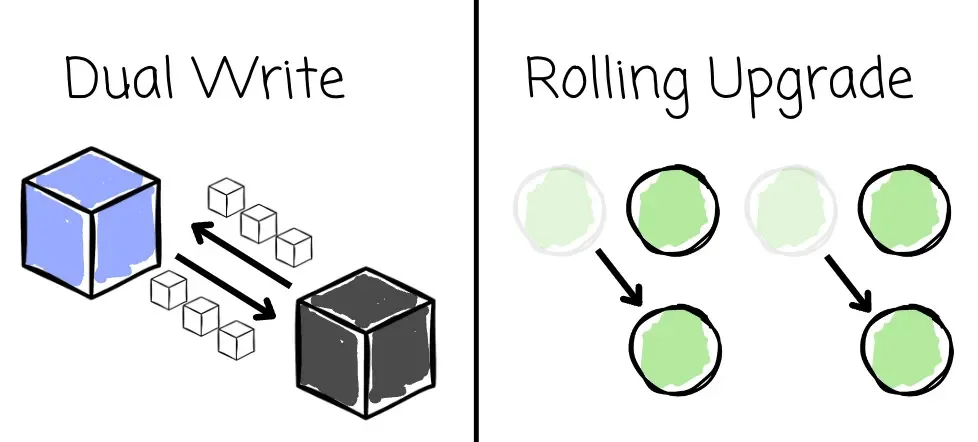
Its goal is to ensure a reliable migration process and native client redirection without downtime.
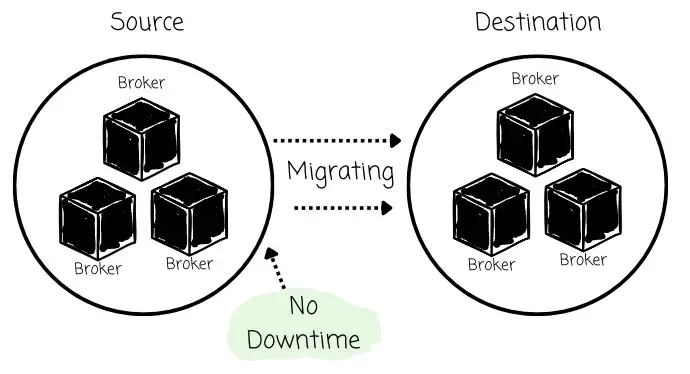
Currently, the solution only supports Kafka-AutoMQ migration; I personally look forward to the support for Kafka-Kafka migration in the future.
Dual write
The key to ensuring continuous operation for the Kafka cluster and clients lies in the dual write mechanism. Written data in Kafka will be synced to AutoMQ, and written data in AutoMQ will also be synced back to Kafka, allowing administrators to roll back safely if the migration process encounters problems.
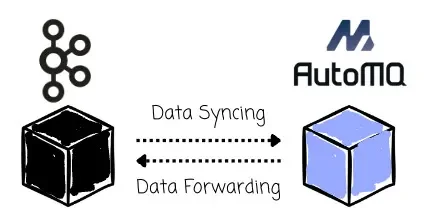
The AutoMQ’s partition leaders are the ones who handle the migration process. They could act as consumers that pull messages from Kafka’s partition leaders for the Kafka-AutoMQ syncing process. In a different direction, they also produce messages back to Kafka’s partition leaders to ensure dual-write.
For each responsibility, the partition leader will be referred to by different roles:
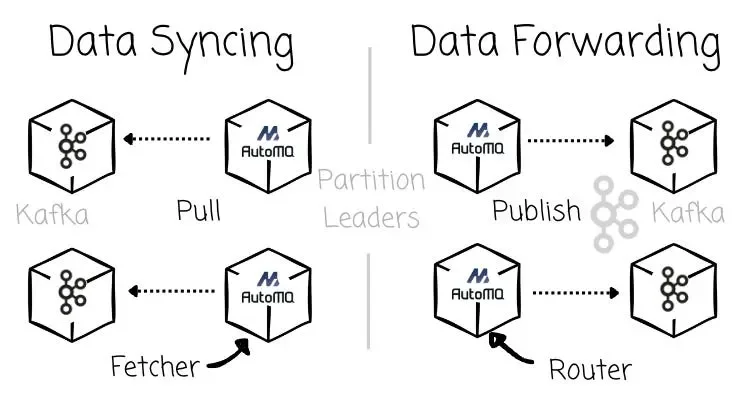
-
Syncing Kafka data to AutoMQ: the fetcher, the AutoMQ’s partition leader, acts as a consumer that fetches data from Kafka.
-
Forwarding AutoMQ data to Kafka: the router, the AutoMQ’s partition leader, acts as a producer that publishes data to Kafka.
Kafka → AutoMQ
To begin the migration process, Kafka Linking requires the source Kafka cluster details, the topics to be migrated, and initial synchronization points (e.g., a complete historical migration, only new data, or at a specific timestamp). AutoMQ will then provision the corresponding topics and partitions within its cluster.
Imagine we have two Kafka topics that need to be migrated:
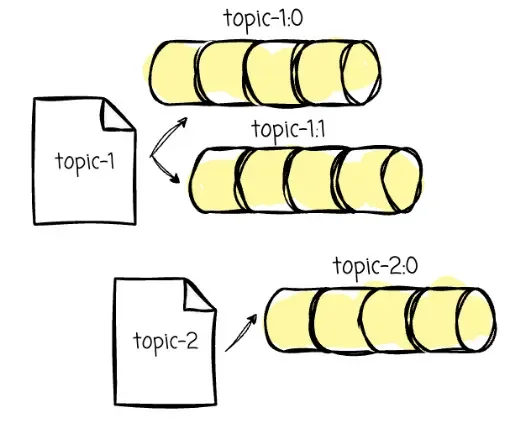
-
topic-1: with 2 partitions (topic-1:0,topic-1:1) -
topic-2: with 1 partition (topic-2:0)
The Kafka Linking continuously monitors the cluster’s state. It detects the changes in the partition leader status to ensure AutoMQ is always interacting with the up-to-date partition leader for the migration process. If the leaders change in the source Kafka cluster, this event is immediately detected. The affected partition is then placed into a “pre-processing queue.”
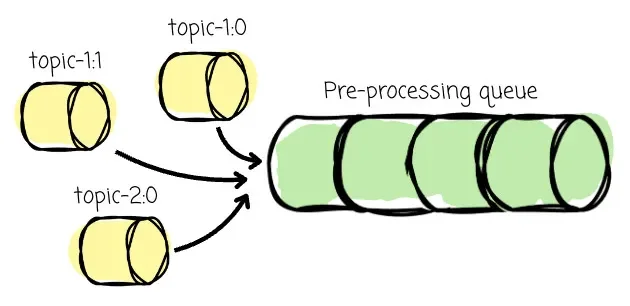
For the initial setup, the Kafka Link places topic-1:0 , topic-1:1, and topic-2:0 in the queue. Then it asynchronously pre-processes these in-queue partitions in the background. For each partition, the Kafka Link:
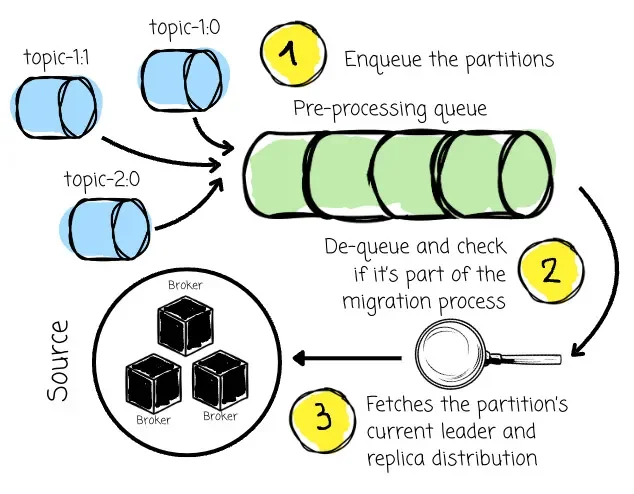
-
Checks its metadata to confirm it’s part of the migration and truly needs synchronization from Kafka → AutoMQ.
-
Establishes a connection to the Kafka cluster and fetches the partition’s current leader and replica distribution to avoid cross-az traffic when fetching data.
-
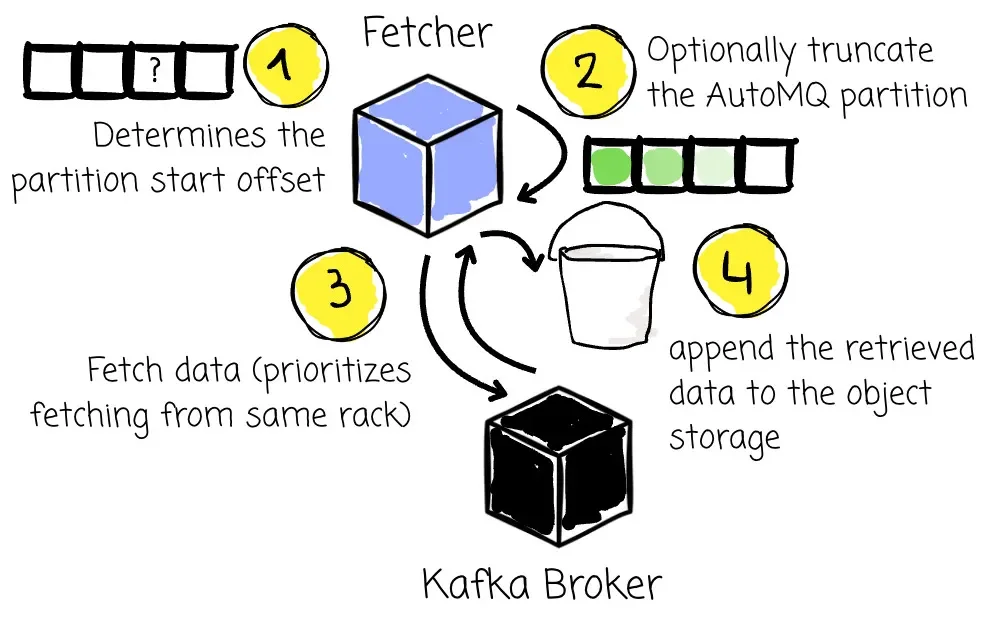
After that, the AutoMQ partition leaders (in this case, the Fetchers) start pulling data from the associated Kafka partition leaders. AutoMQ also prioritizes fetching data on the same rack. The Fetcher then:
-
Determines the partition start offset for the data copying process: If the user chooses
earliest, it gets the offset of the very first message. Fetcher gets the offset of the current last message iflatestis selected. With thetimestampoption, it gets the offset corresponding to that time. -
If a partition is being created in AutoMQ for the first time and the user chooses the
latestortimestampoptions, the Fetcher might internally “truncate” the AutoMQ partition to ensure its starting point aligns with the chosen offset from the source. -
The Fetcher continuously builds fetch requests for a partition to send to its respective leaders in the source Kafka cluster.
-
Like a regular consumer, Fetcher makes these requests incrementally and only asks for new data since its last successful fetch.
-
When the Fetcher receives a response from the source Kafka, it will append the retrieved data to the object storage. If it was a failed response, the Fetcher will retry or take action based on the error type (e.g., requesting the new partition leader if the leader has changed).
-
After the partition’s data is successfully appended to AutoMQ’s storage, the Fetcher ensures that the subsequent request it sends for this partition will pick up precisely from where it left off, guaranteeing no data is missed and preventing duplication. (like a regular consumer)
-
This entire cycle then repeats continuously.
AutoMQ → Kafka
As mentioned, a dual-write mechanism like this enables Kafka Linking to reliably carry out the migration process while keeping clients operational normally. It not only syncs data from Kafka to AutoMQ but also forwards data from AutoMQ back to Kafka:
- When the producers are operating only on Kafka, the data only needs to be synced from Kafka → AutoMQ.
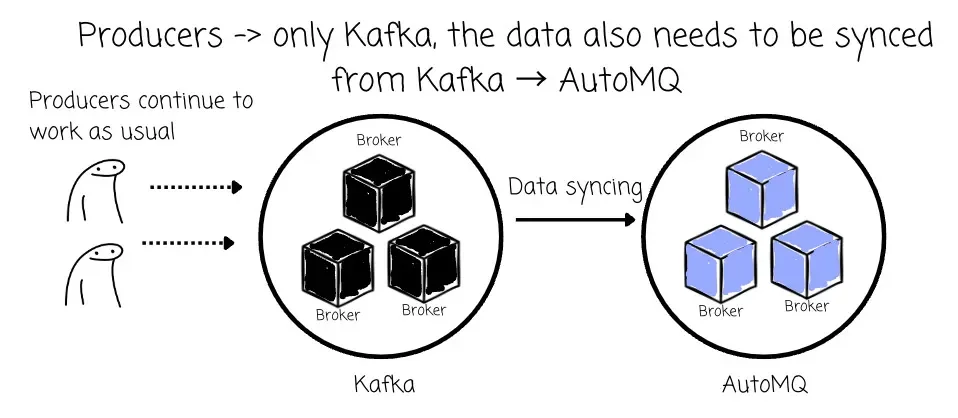
- After the rolling upgrade (will be covered soon), some producers start sending messages to AutoMQ, while remaining producers still process data to Kafka. At this time, data also needs to be forwarded from AutoMQ to Kafka.
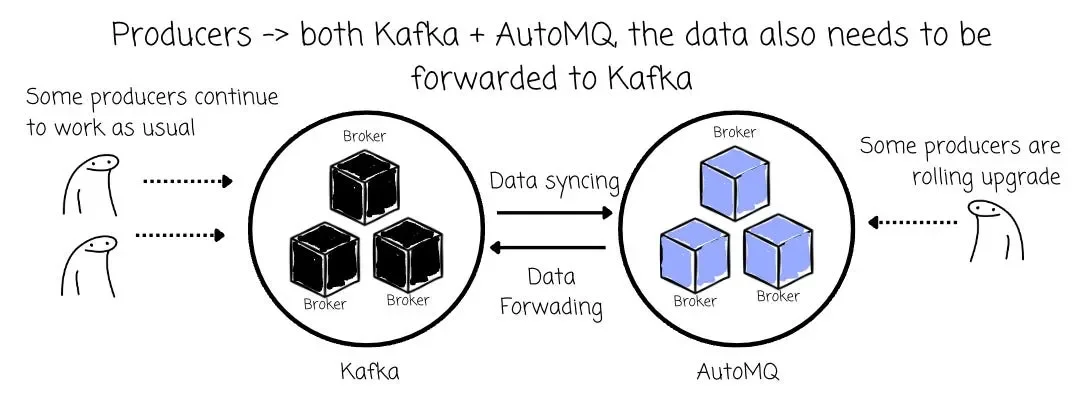
The AutoMQ’s partition leaders (in this case, the Routers) are responsible for the AutoMQ → Kafka message forwarding:
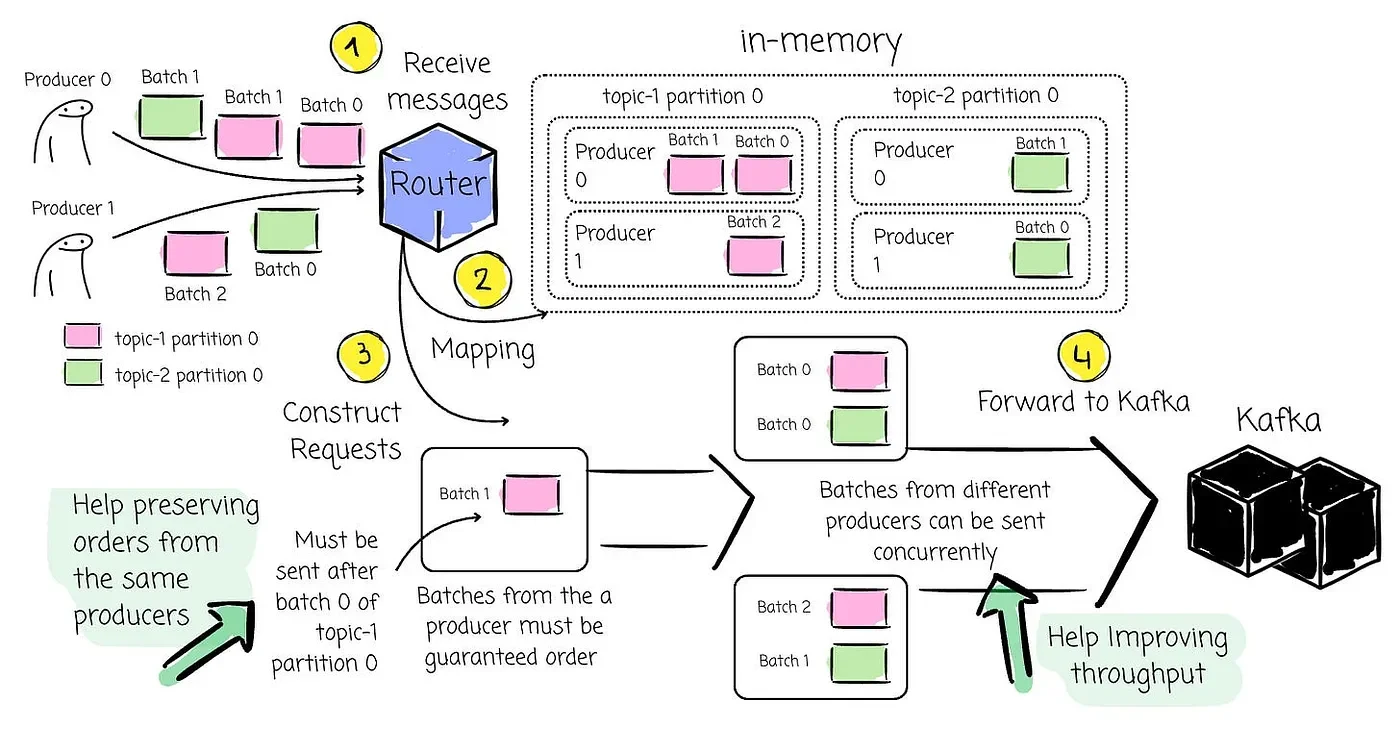
-
The Router first maps the received messages to an in-memory message map that allows for efficient processing and, most importantly, preserves the ordering guarantees.
-
The key for this map is the partition, and the value is a message pool containing all messages pending for sending back to Kafka.
-
Within each partition’s message pool, messages are further grouped by their source producer.
-
Kafka guarantees FIFO (First-In, First-Out) order per producer per partition. By grouping messages by producer within a partition’s pool, the Router can strictly ensure that messages from a producer are forwarded in the exact order they were received.
-
The Router understands that the messages it receives have often already been grouped into batches by the original Kafka producer . It avoids unnecessary re-aggregation of these existing batches for the same partition.
-
When it’s time to construct a new send request to Kafka, it selects one or more complete batches from the relevant partition’s message pool.
-
When the Router completes constructing requests, it sends them to Kafka and starts creating new requests right away. Batches from different producers could be sent concurrently to improve throughput, while batches from the same producer must be sent sequentially to preserve order.
Rolling upgrade
A rolling upgrade is a software deployment strategy that updates a running system to a new version with minimal or zero downtime and reduced risk. Instead of taking the entire system offline to apply the update, a rolling upgrade works by:
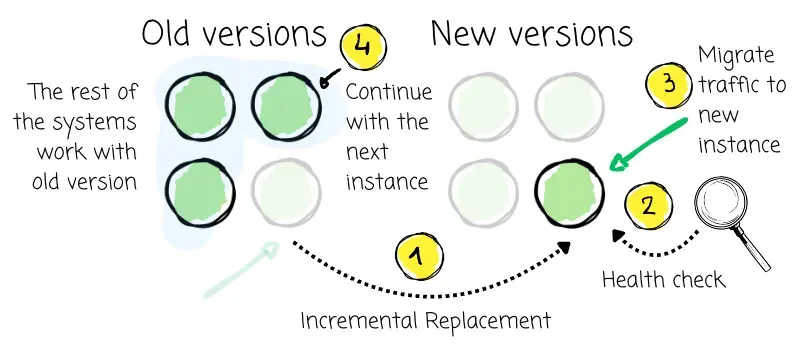
-
Incremental Replacement: Updating a small batch or a single instance of the system at a time.
-
Maintaining Service Availability: During the update, the majority of the system continues to serve requests using the old version.
-
Health Checks and Verification: Each newly updated instance is checked to ensure it’s healthy and functioning correctly before it’s allowed to serve live traffic.
-
Gradual Traffic Shift: Once a new instance is verified, traffic is gradually directed to it, and an old instance can then be safely dropped or updated.
-
Iteration: This process repeats in batches until all instances are running the new version.
-
Easy Rollback: If any issues arise during a batch update, the problematic batch can be quickly rolled back to the previous stable version, limiting the impact to a small subset of the system.
AutoMQ’s Kafka Linking applies the principle of rolling upgrades to the challenging task of Kafka cluster migration, aiming for proper zero-downtime client transitions.
Producer Migration
In traditional migrations, administrators stop all producers, wait for the data to sync, and then restart them, pointing them to the new cluster. This causes downtime.
With Kafka Linking, a subset of producers is rolling upgraded to point to the destination AutoMQ cluster at a time. The rest of the producers continue to send messages to the original Kafka cluster.
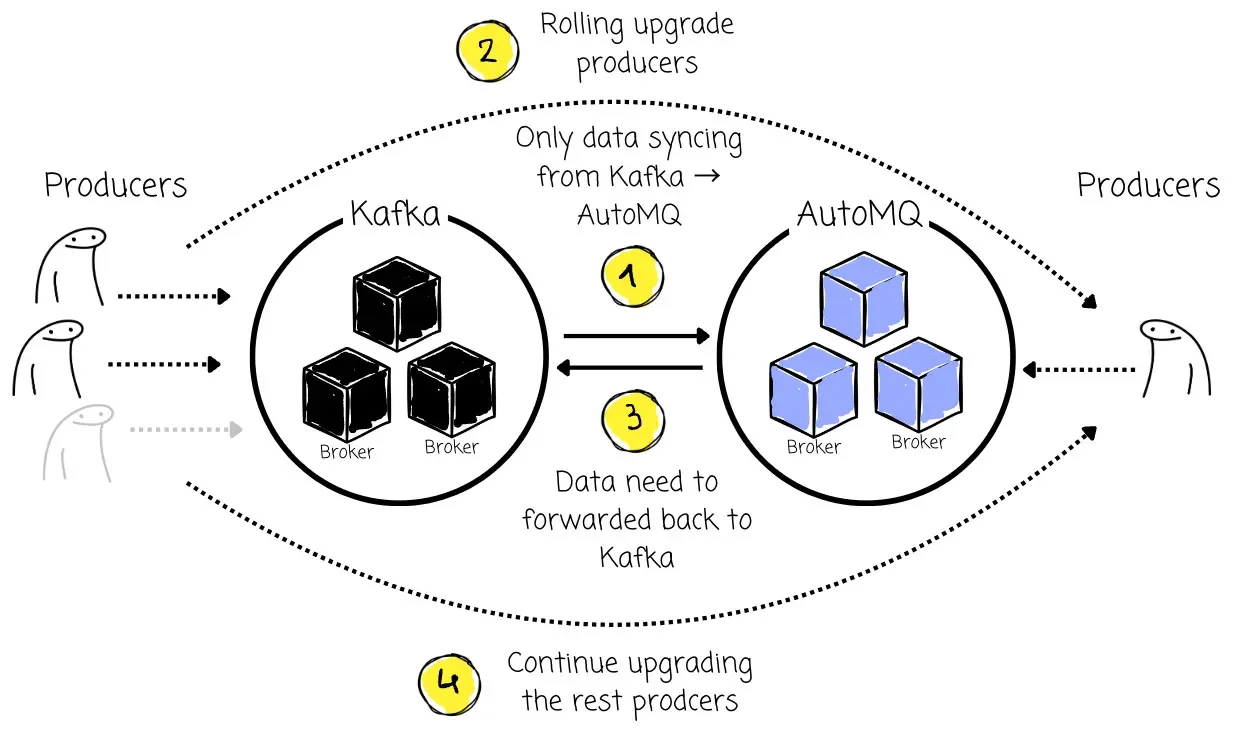
When producers are updated to send messages to the AutoMQ cluster, all messages received from these migrated producers are immediately forwarded back to the source Kafka cluster. This ensures admins can safely roll back these producers to the point where they are back in the Kafka cluster.
This ensures the producers continue to send messages (either to the old cluster or via AutoMQ back to the old cluster). No messages are dropped. The Consumers still connect to the source cluster at this phase and continue to consume all messages, regardless of whether they originated directly from the old producers or were forwarded via AutoMQ. This creates a seamless flow where the Kafka source cluster remains the single source of truth for consumption during this phase.
Consumer Migration
Similar to producers, users perform a rolling upgrade on their consumer applications, one by one or in batches, to point them to the AutoMQ cluster.
Crucially, when a consumer connects to the AutoMQ cluster during this phase, AutoMQ disables reading for that consumer to prevent duplicate data consumption. If AutoMQ immediately allowed reading and the consumer group was still partially active on the source, it could result in consuming messages more than once.
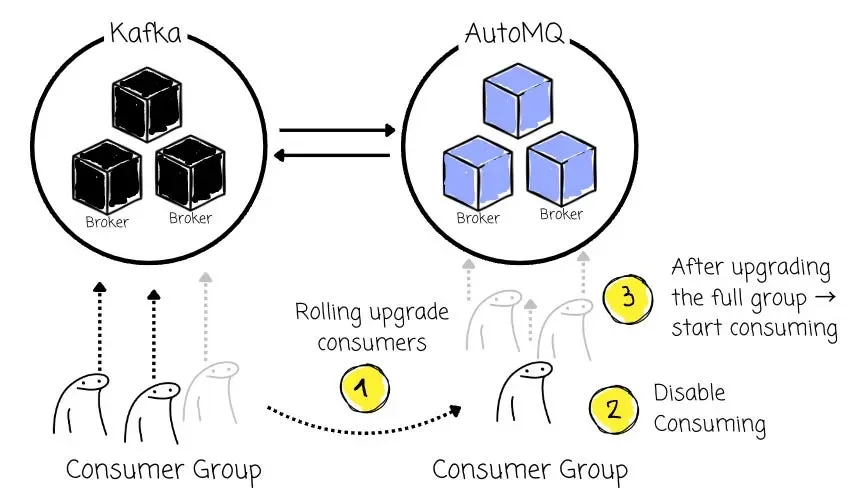
Once all consumers in a specific Consumer Group have been successfully redirected (via rolling upgrade) and are detected as offline from the source cluster, Kafka Linking synchronizes the consumer offset of that Consumer Group from the source cluster. This ensures the AutoMQ-connected consumers can pick up exactly where they left off in the original cluster, preventing duplicates or missed messages.
After that, Kafka linking enables reading for that consumer group. Consumers now connected to AutoMQ can resume consumption seamlessly from the correct offset.
The above process is managed by the AutoMQ control plane. It can monitor the status and automatically promote the consumer group, which makes the process seamless.
Topic Migration
Once producers and consumers for a specific topic (e.g., topic-a) have fully completed their rolling upgrades and are operating via AutoMQ (meaning producers are forwarding to AutoMQ, which then forwards back to the source, and consumers are reading via AutoMQ after group promotion), the user can manually promote the topic:
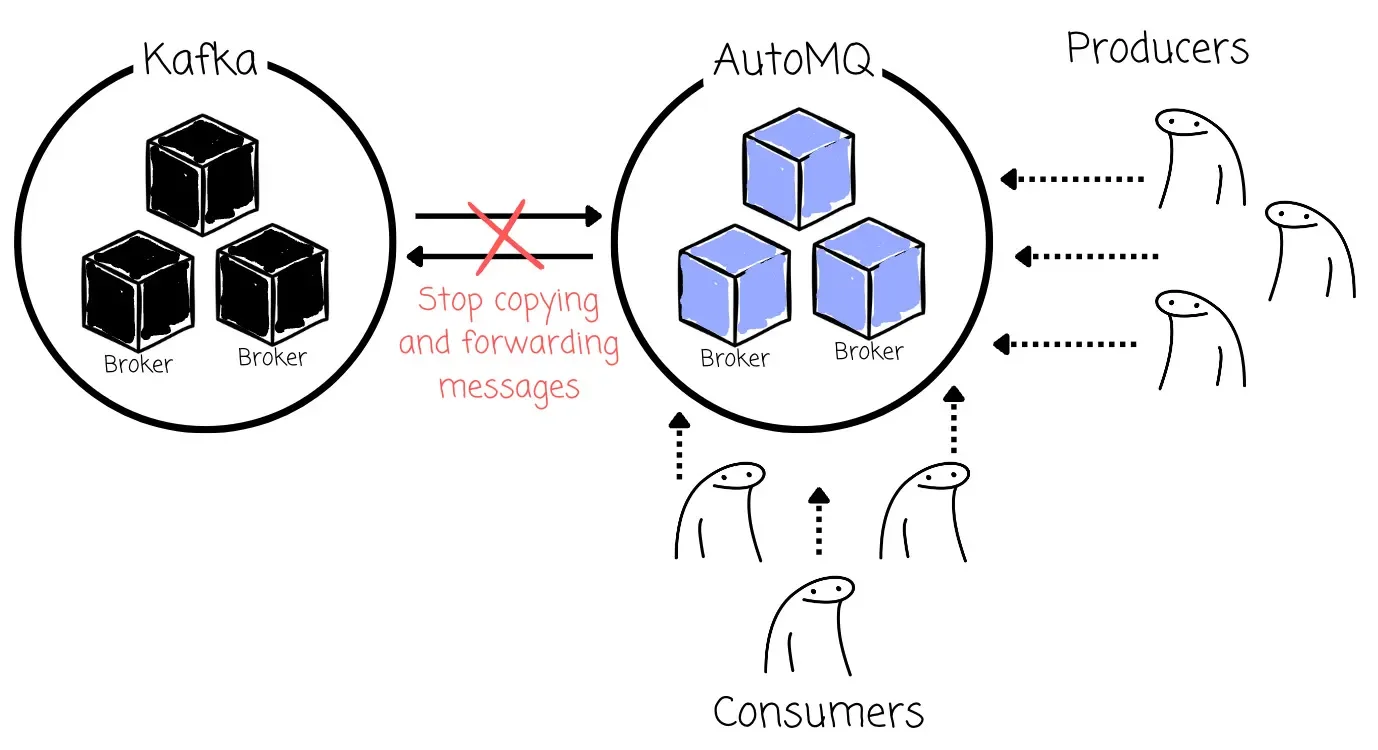
-
AutoMQ stops copying messages from the source cluster for this topic
-
AutoMQ stops forwarding new messages back to the source cluster for this topic
-
The AutoMQ cluster now becomes the definitive, standalone cluster for this topic, handling both reads and writes directly without relying on the source cluster.
Other topics can follow the same rolling migration process in batches, ensuring a controlled, zero-downtime transition for the entire Kafka deployment.
Outro
Thank you for reading this far.
In this article, we learn about the typical approach of the available Kafka migration tool, which could cause data downtime and increase operational complexity. Then, we explore the solution from AutoMQ, the Kafka Linking, which guarantees a reliable migration process while keeping related applications operational without downtime.
Now, see you next time.
Reference
**Kafka Replication Without the (Offset) Gaps
AutoMQ,Beyond MirrorMaker 2: Kafka Migration with Zero-Downtime(2025)


