


.png)
Introduction
Are you currently using IBM MQ? Do you find yourself constrained by its complex licensing structures and the challenges of integrating it with modern, high-throughput data streams [7]?
If you've considered exploring alternatives, your instincts are correct. Today’s enterprise data landscape has decisively shifted toward real-time event streaming, and traditional message-oriented middleware is facing unprecedented challenges in this new domain [2, 4]. Businesses require platforms that can handle massive data volumes, support real-time analytics, and integrate effortlessly with the cloud-native ecosystem.
This article will explore the rationale for migrating from IBM MQ, analyze the advantages of moving to the industry-standard Apache Kafka, and introduce a modern, cloud-native streaming solution that not only simplifies the migration process but also unlocks significant cost efficiencies and operational elasticity.
Why Consider a Migration? The "Pain Points" of IBM MQ
As a mature enterprise messaging solution, IBM MQ has a long history of reliability and transactional integrity. However, as business requirements evolve toward real-time data processing, its traditional architecture reveals several "pain points":
Complex Pricing and High Total Cost of Ownership (TCO) IBM MQ's licensing model is often tightly coupled to its underlying hardware resources (e.g., Processor Value Units, or PVUs) [3, 7]. In a dynamic cloud environment, this pricing model can be unpredictable, leading to high costs and a lack of flexibility. Furthermore, this proprietary model can result in deep vendor lock-in, limiting an organization's technological freedom.
Architectural Mismatch for Streaming IBM MQ was designed as Message-Oriented Middleware (MOM), with its core strength in reliable, transactional point-to-point message delivery [5, 6]. It uses a "push" model and queue-based storage, where messages are typically deleted after consumption. This "store-and-forward" architecture is well-suited for traditional Enterprise Application Integration (EAI), but it is not optimal for the high-throughput, persistent storage, and replayable "pull" model log paradigm required by modern event streaming applications [4].
Ecosystem and Integration Limitations While IBM MQ has a mature ecosystem, integrating it with the rapidly evolving landscape of modern data tools—such as data lakes, real-time analytics platforms, and various SaaS applications—can be more complex than with platforms designed natively for connectivity [2]. Modern data architectures demand seamless, low-latency data flow between systems, which is a core strength of event streaming platforms.

The Modern Alternative: Apache Kafka
As the open-source distributed streaming platform, Apache Kafka has become the de facto standard for building real-time data pipelines and streaming applications [3]. It offers a fundamentally different solution:
An Open-Source Standard Built for Streaming At its core, Kafka is a distributed, immutable commit log architecture. This design is built for horizontal scaling, high fault tolerance, and massive throughput, capable of processing millions of messages per second [6]. It allows data to be captured, stored, and processed as a continuous stream.
A Rich and Extensible Ecosystem Kafka's power lies not just in its core but also in its thriving ecosystem, especially Kafka Connect. Kafka Connect provides a standardized, scalable framework for reliably streaming data between Kafka and hundreds of other data systems, such as databases, key-value stores, search indices, and cloud object storage [1].
Enabling New Data Use Cases Unlike a traditional queue, Kafka's persistent log allows data to be retained for long periods (based on time or size policies) and to be read independently and repeatedly by multiple consumer groups [6]. This feature enables powerful use cases such as event sourcing, stream processing, and log aggregation [2].
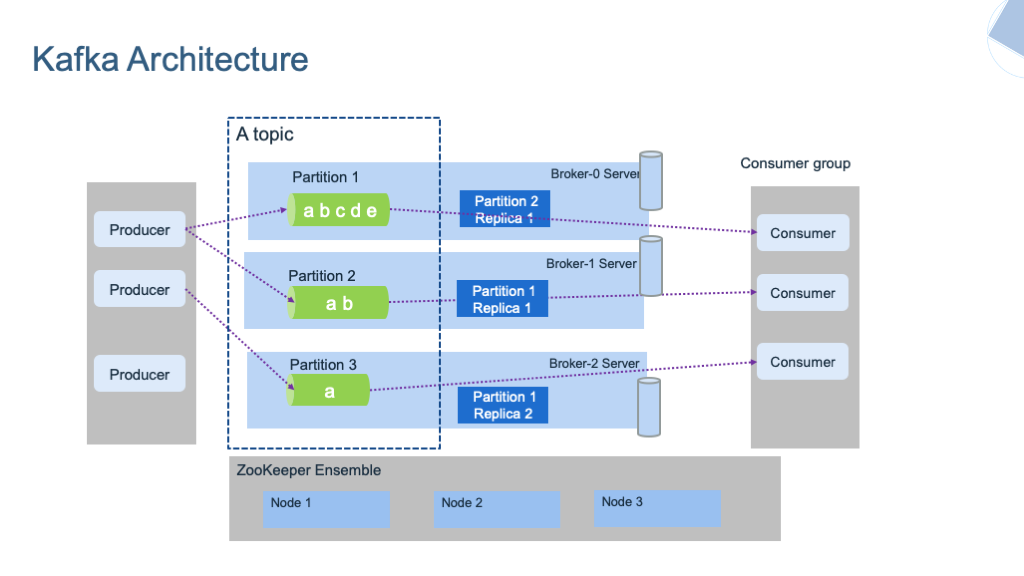
The Value Bridge: From Kafka's Challenges to a Cloud-Native Solution
However, migrating to Apache Kafka is not without its own challenges. When deploying and managing open-source Kafka at scale, enterprises quickly encounter a new set of complexities:
High Operational Overhead: Managing Kafka brokers, ensuring partition balancing, and handling failover all require significant expertise and manual effort.
Surging Cloud Costs: When running Kafka in the cloud, one of the biggest cost drivers is storage. Kafka's "shared-nothing" architecture couples compute with local storage, leading to rapidly escalating costs as data volume grows.
Cross-Availability Zone (AZ) Traffic Fees: For high availability, Kafka's replication mechanism copies data between different availability zones, which generates high and often unpredictable cross-AZ network traffic costs.
Lack of Elasticity: Kafka's stateful architecture makes rapid elasticity difficult. Scaling a cluster up or down is a slow, complex, and high-risk process because it requires physically moving and copying massive amounts of data.
This is precisely where a solution is needed—one that maintains Kafka's powerful API compatibility but re-architects its core for the cloud. AutoMQ is a new-generation, cloud-first Kafka service based on object storage. It is 100% compatible with the Apache Kafka API, allowing existing tools like Flink and Spark to integrate seamlessly without modification.
AutoMQ fundamentally solves Kafka's core challenges through its innovative compute-storage separation architecture.
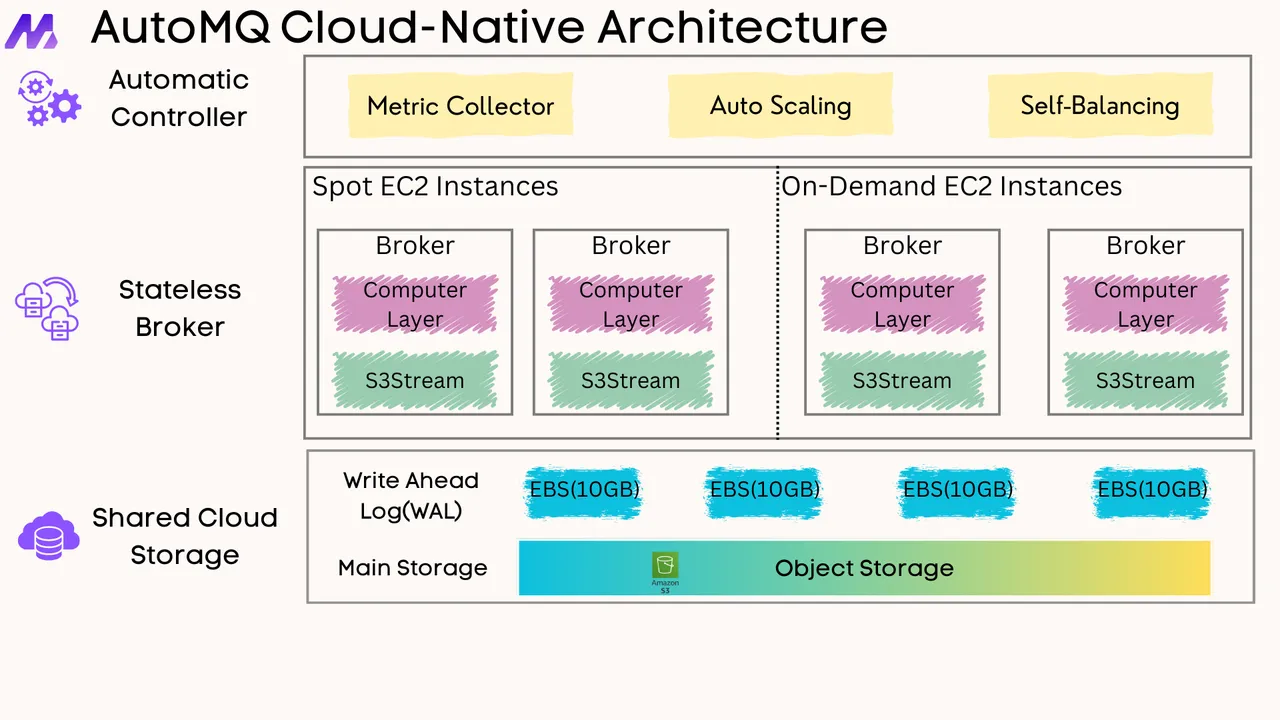
Massive Cost Savings (Over 90%) AutoMQ offloads data to cloud object storage (like S3) instead of expensive local disks. This "S3Stream" engine allows for infinite, on-demand capacity and a pay-as-you-go model.
Benchmark Example: In a test scenario with 1GB/s average write throughput and 3-day data retention, AutoMQ's monthly costs were drastically lower than Apache Kafka's.
Storage: $3,462 (AutoMQ) vs. $20,229 (Kafka).
Network: $15 (AutoMQ) vs. $39,960 (Kafka).
How it works: AutoMQ's multi-write architecture completely avoids the cross-AZ data replication traffic that plagues traditional Kafka, eliminating these substantial network costs.
Real-World Example: By adopting AutoMQ, JD.com reduced its cluster storage costs by 50% and its bandwidth costs by 33%. Similarly, Geely Auto achieved a TCO reduction of over 50%.
Unprecedented Elasticity: AutoMQ's architecture makes its compute brokers stateless. This solves Kafka's most significant operational pain point: scaling. Because data is not tied to the brokers, partition migration is a near-instant metadata update rather than a massive data-copying operation.
Benchmark Example: Partition migration time with AutoMQ is 1.5 seconds , compared to 3 hours for traditional Kafka. Traffic balancing completes in 1 minute , versus 43 hours for Kafka.
Real-World Example: The Grab case study demonstrates this power. Their cluster partition migration time was reduced from 6 hours to less than 1 minute , allowing them to scale compute resources dynamically without impacting performance.
High Performance and Modern Integration This new architecture does not sacrifice performance. The commercial version of AutoMQ supports low-latency messaging with a P99 of less than 10ms. It also embraces modern data architectures with built-in integration for data lakes like Apache Iceberg, enabling ZeroETL and one-click query analysis.
Conclusion
Migrating from a traditional system like IBM MQ is a significant strategic decision. While Apache Kafka offers a powerful, future-proof paradigm for stream processing, its operational complexity and total cost in a cloud environment cannot be ignored.
A cloud-native solution like AutoMQ offers the best of both worlds: it is 100% compatible with the Kafka ecosystem, making migration seamless. Simultaneously, its ground-up cloud-native redesign—featuring compute-storage separation—fundamentally solves the critical pain points of cost , elasticity , and operations. This isn't just an infrastructure modernization; it's a leap forward in cost-efficiency and operational excellence.
Ready to simplify your Kafka migration and dramatically reduce your streaming costs? Start exploring AutoMQ today to experience the true power of cloud-native Kafka.
References
Message Broker and Apache Kafka: Trade-Offs, Integration, Migration
IBM MQ vs Apache Kafka: Choosing the Best for Message Queuing and Event Streaming
Interested in our diskless Kafka solution AutoMQ? See how leading companies leverage AutoMQ in their production environments by reading our case studies. The source code is also available on GitHub.

Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging





