
TL;DR
Migrating a live Kafka cluster requires a carefully planned approach to maintain service availability and ensure data integrity. This post examines two tools for this purpose: MirrorMaker 2 and AutoMQ Kafka Linking. MirrorMaker 2 is a replication tool that functions by copying data, necessitating a coordinated manual cutover of clients.
In contrast, Kafka Linking integrates replication directly into the target cluster and is designed to manage the client transition through an automated, phased process. This automated design aims to simplify the migration and eliminate the service downtime associated with manual cutovers.
Core Difficulties in Kafka Migration
Successfully migrating a Kafka cluster requires addressing several key challenges. The following are three of the primary difficulties that teams commonly encounter:
-
Ensuring Data Integrity and Minimizing Downtime: The most critical challenge is guaranteeing data integrity—ensuring no messages are lost or duplicated—while minimizing downtime. For many applications with at-least-once or exactly-once delivery needs, a prolonged outage is not an option. This makes a "big bang" approach, where services are stopped for the migration, impractical for most use cases.
-
Managing Consumer Offset Translation: A significant technical hurdle is managing consumer offset translation. Consumer groups track their reading progress via committed offsets, which must be accurately carried over to the new cluster. If handled incorrectly, consumers might reprocess large volumes of data or, worse, skip messages entirely, leading to data loss and inconsistency.
-
Data Replication and Synchronization: The physical act of replicating topic data, especially with large volumes, presents a substantial challenge. The replication process must be efficient enough to copy historical data while keeping up with the real-time data flow. This requires careful selection of a replication tool and sufficient network bandwidth to avoid impacting the performance of the live source cluster.
A Traditional Solution: MirrorMaker 2
One of the primary tools provided within the Apache Kafka ecosystem for migration is MirrorMaker 2 (MM2). It is designed to replicate data and topic configurations from a source cluster to a target, making it a common choice for executing a migration, creating a standby cluster for disaster recovery, or aggregating data from multiple locations. Built on the Kafka Connect framework, MM2 operates as an independent service to manage the complex tasks of synchronization.
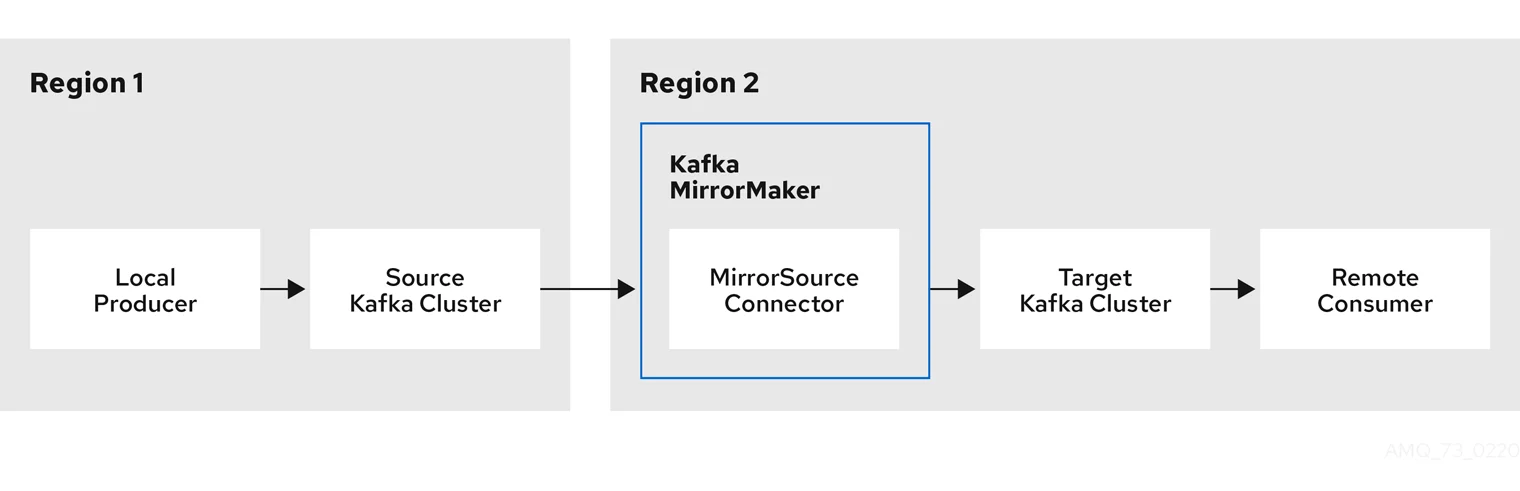
The Migration Workflow
Executing a migration with MirrorMaker 2 follows a structured, multi-stage process designed to move data while the source cluster remains operational.
-
Deployment and Configuration The process begins with deploying an MM2 instance and configuring it with the connection details for both the source and target Kafka clusters. In this stage, administrators define which topics to replicate, typically using an allowlist or regular expressions to select the desired data streams.
-
Data Replication and Offset Synchronization Once started, MM2 initiates the core replication tasks. Its internal connectors work in parallel to:
-
Replicate Data: A
MirrorSourceConnectorreads data from the source topics, and aMirrorSinkConnectorwrites this data to the target cluster. This process copies all historical data first and then continues to replicate new messages in near real-time. By default, it creates topics on the target cluster prefixed with the source cluster's name (e.g.,source.my-topic). -
Sync Offsets: A
MirrorCheckpointConnectortracks consumer group progress on the source cluster. It periodically translates these offsets and saves them to the target cluster, which is essential for ensuring consumers can resume from the correct position after the switch.
-
-
Coordinated Cutover The final transition requires careful coordination to prevent data loss or reprocessing.
-
First, producer applications connected to the source cluster are stopped.
-
A brief waiting period allows MM2 to replicate any lingering messages to the target.
-
Next, consumer applications are stopped, reconfigured to point to the new cluster's address, and then restarted.
-
-
Finalization and Decommissioning Upon restart, the reconfigured consumer applications use the translated offsets to begin fetching messages from the correct position in the new cluster. After the team verifies that the new system is stable and performing as expected, the MM2 process can be terminated, and the old source cluster can be safely decommissioned.
Cons of the MirrorMaker 2
While a standard tool, MirrorMaker 2 (MM2) presents significant disadvantages in a migration context due to its operational complexity and high-risk cutover process. It requires deploying and managing a separate Kafka Connect cluster, which consumes its own resources and needs careful tuning. Furthermore, its default behavior of renaming topics with a prefix is intrusive, forcing application-side code and configuration changes to handle the new names.
The greatest challenge is the manual cutover. This multi-step procedure of stopping and restarting clients in a coordinated sequence is highly susceptible to timing errors. If consumer offsets are not perfectly synced before the switch, it can easily lead to either reprocessing messages (duplicates) or skipping them entirely (data loss). This complexity makes guaranteeing a clean, zero-data-loss migration a significant challenge for any team.
A New Approach: Zero-Downtime Migration with Kafka Linking
Given the operational complexities and risks of traditional replication tools, the need for a more streamlined migration strategy is clear. This is where a modern solution like AutoMQ's Kafka Linking comes into the picture. It is a fully managed, cross-cluster data synchronization feature designed specifically to address the core pain points of migration, enabling a true zero-downtime experience.
What is Kafka Linking?
At its core, Kafka Linking is a built-in replication technology that synchronizes data, metadata, and consumer offsets from a source Kafka cluster to a target AutoMQ cluster. Unlike MirrorMaker 2, which runs as an entirely separate system that you must deploy and manage, Kafka Linking is an integrated part of the target AutoMQ platform. This native integration is a key differentiator, as it eliminates the need for deploying and maintaining additional components or connectors and moves the responsibility of replication from a self-managed tool to a fully managed cloud service.
You can find more technical details behind Kafka Linking in this blog: Beyond MirrorMaker 2: Kafka Migration with Zero-Downtime.
Kafka Linking vs. MirrorMaker 2
The fundamental differences between Kafka Linking and MirrorMaker 2 become clear when compared side-by-side. The modern approach rethinks the entire workflow to eliminate the most problematic aspects of traditional replication.
| Feature | MirrorMaker 2 | AutoMQ Kafka Linking |
|---|---|---|
| Deployment | Requires a separate, self-managed Kafka Connect cluster. | Fully managed and integrated into the target AutoMQ cluster. |
| Cutover Process | A manual, multi-step process requiring downtime for producers and consumers. | A single rolling update for clients with automated traffic switching. |
| Data Consistency | At-least-once delivery; risk of duplicates or data loss during cutover. | Preserves data ordering and integrity with a backward forwarding mechanism. |
| Client Application | Requires topic name changes in code (e.g., source.my-topic). | No changes required to client code; topics retain their original names. |
The Benefits of a Modern Migration Solution
Kafka Linking was engineered to directly counteract the primary weaknesses of MirrorMaker 2. Instead of a high-risk, manual cutover, it offers a guided, automated workflow that delivers tangible benefits.
-
True Zero-Downtime Migration: This is the most significant advantage. Kafka Linking allows client applications to be migrated via a single, continuous rolling upgrade. There is no "stop-the-world" phase, which means both producers and consumers can operate without service interruption throughout the entire process.
-
Fully Automated and Simplified Workflow: The migration lifecycle is managed and automated through the AutoMQ console. Kafka Linking handles the creation of topics, synchronization of data, and the final cutover. It uses automated checks and promotion phases to safely switch traffic, which drastically reduces the risk of human error and eliminates the complex coordination required for a manual cutover.
-
Seamless Producer Migration: During the migration, data produced to the new AutoMQ cluster is automatically forwarded to the original source cluster. This unique capability means producers can be migrated first without affecting consumers that are still connected to the old cluster. It ensures a consistent, ordered stream of data is available to all consumers, regardless of which cluster they are pointing to.
-
Non-Intrusive Application Integration: Kafka Linking replicates topics while preserving their original names. This removes a significant burden from application teams, as no code modifications are needed to handle new topic prefixes. The only change required is updating the broker address in the client configuration, making the entire process far less intrusive and easier to manage.
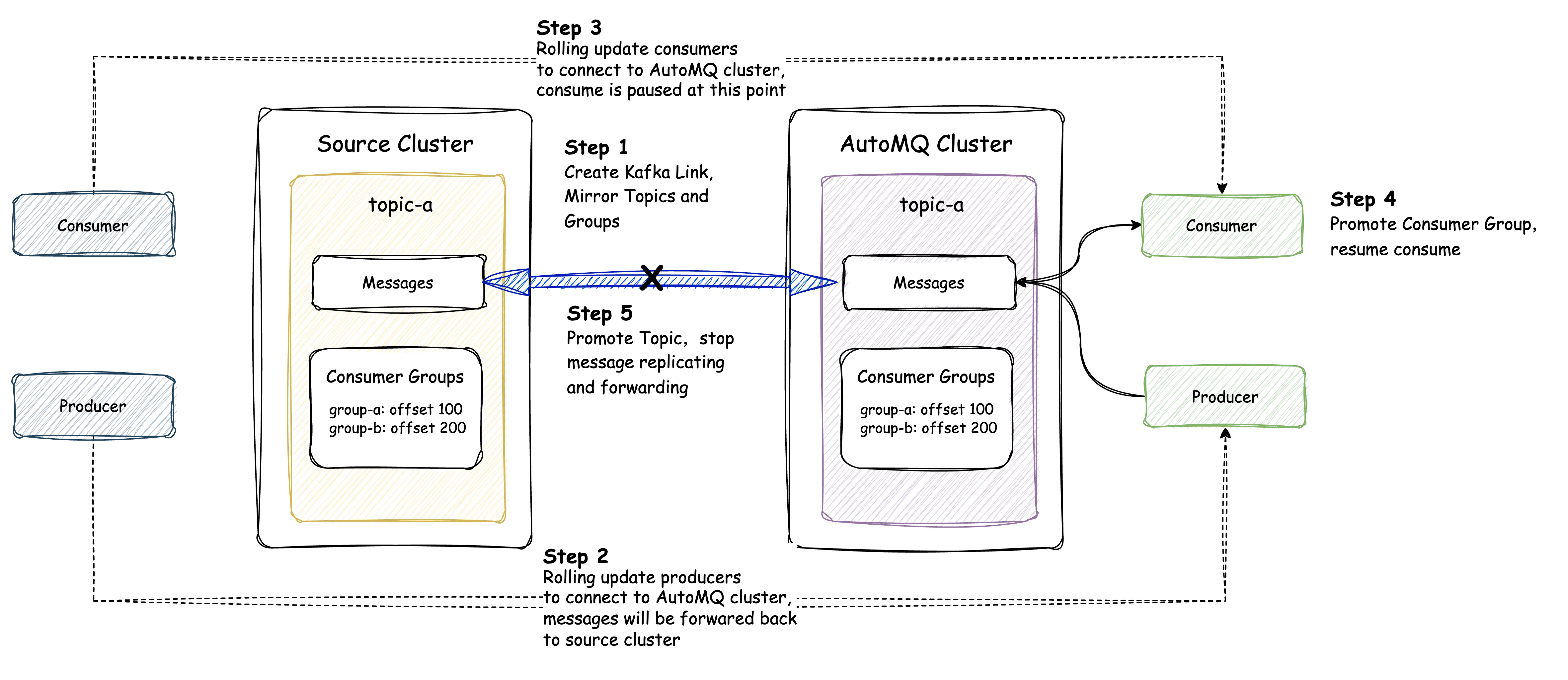
The Kafka Linking Migration Workflow
The Kafka Linking migration process is designed as a structured, phased workflow that moves from initial setup to a seamless, automated cutover. The entire process is managed from the AutoMQ console and eliminates the need for manual client coordination.
Phase 1: Initial Setup and Synchronization
-
Create a Kafka Link: The first step is purely configuration. In the AutoMQ console, you define a "Kafka Link" that stores the connection information for your source Kafka cluster. No data is moved at this stage.
-
Create Mirror Topics: For each topic you intend to migrate, you create a corresponding "mirror topic" on the AutoMQ cluster. This action initiates the data replication process. At this point, the Fetcher component begins pulling all historical and real-time data from the source topic.
-
Create Mirror Consumer Groups: Similarly, you create a "mirror consumer group" on AutoMQ for each group you plan to migrate. This registers the group for the eventual offset synchronization but does not yet enable consumption.
Phase 2: Live Migration of Clients
This phase involves a rolling update of your client applications, which can be done without service downtime.
-
Migrate Producers: Begin by updating your producers one by one (via a rolling restart) to point to the new AutoMQ cluster's broker address. As each producer is migrated, the Router component transparently forwards its messages back to the source cluster. This ensures that consumers still connected to the old cluster continue to receive data without interruption.
-
Migrate Consumers: Next, perform a rolling update of your consumer applications to point them to the AutoMQ cluster. During this process, Kafka Linking keeps the new consumers in a standby state and does not allow them to fetch messages, preventing any duplicate processing.
Phase 3: Automated Cutover and Finalization
This final phase is managed by the Kafka Linking service to ensure a safe and consistent transition.
-
Consumer Group Promotion: Once the system detects that all consumers in a group have been successfully migrated, it automatically triggers the "Consumer Group Promotion." The service syncs the final committed offsets from the source cluster and then enables the consumers on the AutoMQ cluster, which begin processing messages exactly where they left off.
-
Topic Promotion: After you have verified that all producers and consumers are stable on the new cluster, you initiate the final step by triggering a "Topic Promotion." This command cleanly severs the link to the source cluster, stops the Fetcher and Router components, and completes the migration for that topic.
Conclusion
Migrating a live Kafka cluster is a substantial undertaking, where the primary challenges are avoiding downtime and guaranteeing data integrity. While traditional tools like MirrorMaker 2 provide a replication path, they demand significant operational overhead and rely on a high-stakes manual cutover process that can put data at risk.
Modern solutions like AutoMQ's Kafka Linking offer a fundamentally different approach. By integrating data synchronization directly into the target cluster and using an automated, phased process to cut over clients, Kafka Linking eliminates the "stop-the-world" event typical of older methods. This results in a true zero-downtime migration that is simpler, safer, and removes the element of human error from the most critical phases of the process.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


